Most content advice tells you to write better. Longer, clearer, more thorough. That advice is not wrong — it is aimed at the wrong gate.
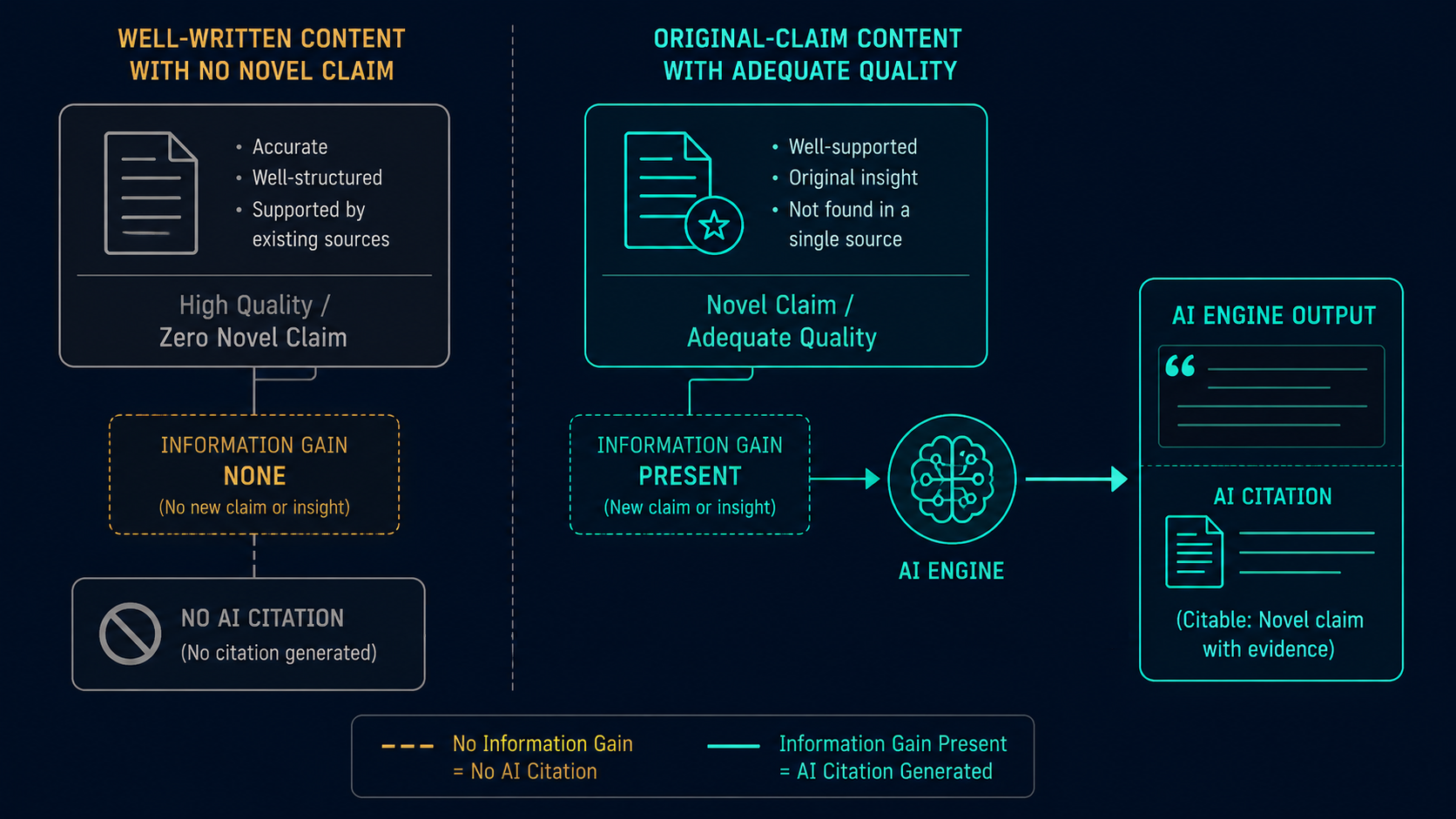
AI retrieval systems — Perplexity, ChatGPT, Google AI Overviews — do not rank content by how well it is written. They rank it by whether it contains something the existing corpus does not. A polished 3,000-word article restating consensus gets passed over. A 900-word piece contributing one non-obvious claim gets cited. The difference is not quality. It is Information Gain.
Information Gain, in the context of AI retrieval, is the measurable delta between what your content contributes and what already exists at competing URLs. It is the primary signal at the LLMO layer of the Citation Architecture — and it is the signal most content teams have no process for generating. Writing quality controls readability after retrieval. Information Gain controls whether retrieval happens at all.
Researchers at Princeton University and collaborating institutions confirmed this directly. In “GEO: Generative Engine Optimization” [Aggarwal et al., 2024, arXiv:2311.09735], a study of ten content modification strategies across 10,000 AI engine queries, adding citations, authoritative sources, and novel information significantly outperformed fluency optimization — the improvement of writing quality alone — as a citation-increasing strategy. As of May 2026, fluency optimization remains among the least effective single interventions for AI citation probability [Aggarwal et al., 2024]. The quality of the prose is not what gets retrieved.
What Is Information Gain and Why Do AI Systems Score It?
Information Gain is not a metaphor. It is a technical property that AI retrieval systems measure — consciously or by proxy — when deciding which sources to surface.
The underlying mechanic: Retrieval-Augmented Generation (RAG) pipelines retrieve candidate documents based on semantic similarity to the query. When multiple documents are semantically similar — when the top twenty results on a topic all say roughly the same thing — the system needs a secondary filter. That filter is novelty. Content that says something the other retrieved documents do not say is more likely to be cited, because citing it adds information to the synthesized answer rather than duplicating existing citations.
This is why high-domain-authority sites with generic content are losing AI citations to newer sites with specific, original claims. Domain authority controlled Google PageRank. It does not control RAG retrieval scoring. What controls RAG retrieval is entity density, freshness, and source authority markers — the retrieval-layer signals of the Citation Architecture — and, at the extraction layer, whether the content contributes a claim worth including.
The implication is direct: if a content strategy is built around “write better than competitors,” it is optimizing for a signal AI systems do not weight heavily. Winning that competition does not determine the citation outcome. The Aggarwal et al. [2024] GEO study confirmed that fluency optimization ranked among the least effective strategies tested for improving citation probability across 10,000 queries.
Why “Write Better Content” Is the Wrong Prescription
The “write better” prescription comes from an era when Google’s ranking signals rewarded depth, readability, and E-E-A-T markers. Those signals still matter for indexing and initial retrieval. They are prerequisites — not differentiators. They get content into the retrieval pool. They do not determine what gets cited from it.
The specific failure mode: a content team researches the top ten results for a target keyword. They identify what each competitor covers. They produce an article that covers all of it, more thoroughly, with better formatting, clearer headings, and proper citations. The article is objectively better written. It receives fewer AI citations than a competitor’s thinner article that contained one specific, non-obvious, verifiable claim.
The reason is structural. When an AI system synthesizes an answer, it selects sources that together produce a complete answer. If a comprehensive article says everything the other articles already say, it adds nothing to the synthesis. The AI cites sources that fill gaps — not the source that covers all gaps most elegantly.
Aggarwal, Murahari, and Rajpurohit at Princeton University demonstrated this mechanically [Aggarwal et al., 2024]: across ten tested content modification strategies, those that added novel information to AI engine responses — citations, statistics, authoritative sourcing — significantly outperformed strategies that improved writing fluency. Fluency optimization was one of the weakest performers across 10,000 queries. The agencies prescribing depth and quality as the primary citation lever are prescribing an intervention that ranks near the bottom of the evidence.
The correct prescription adds a prior step: before the quality pass, identify what the article will contribute that the existing corpus does not contain. Quality makes cited content readable. Information Gain determines whether it gets cited. These are different problems with different solutions, and only one is currently missing from most content workflows.
The Three Information Gain Types That AI Systems Can Extract and Cite
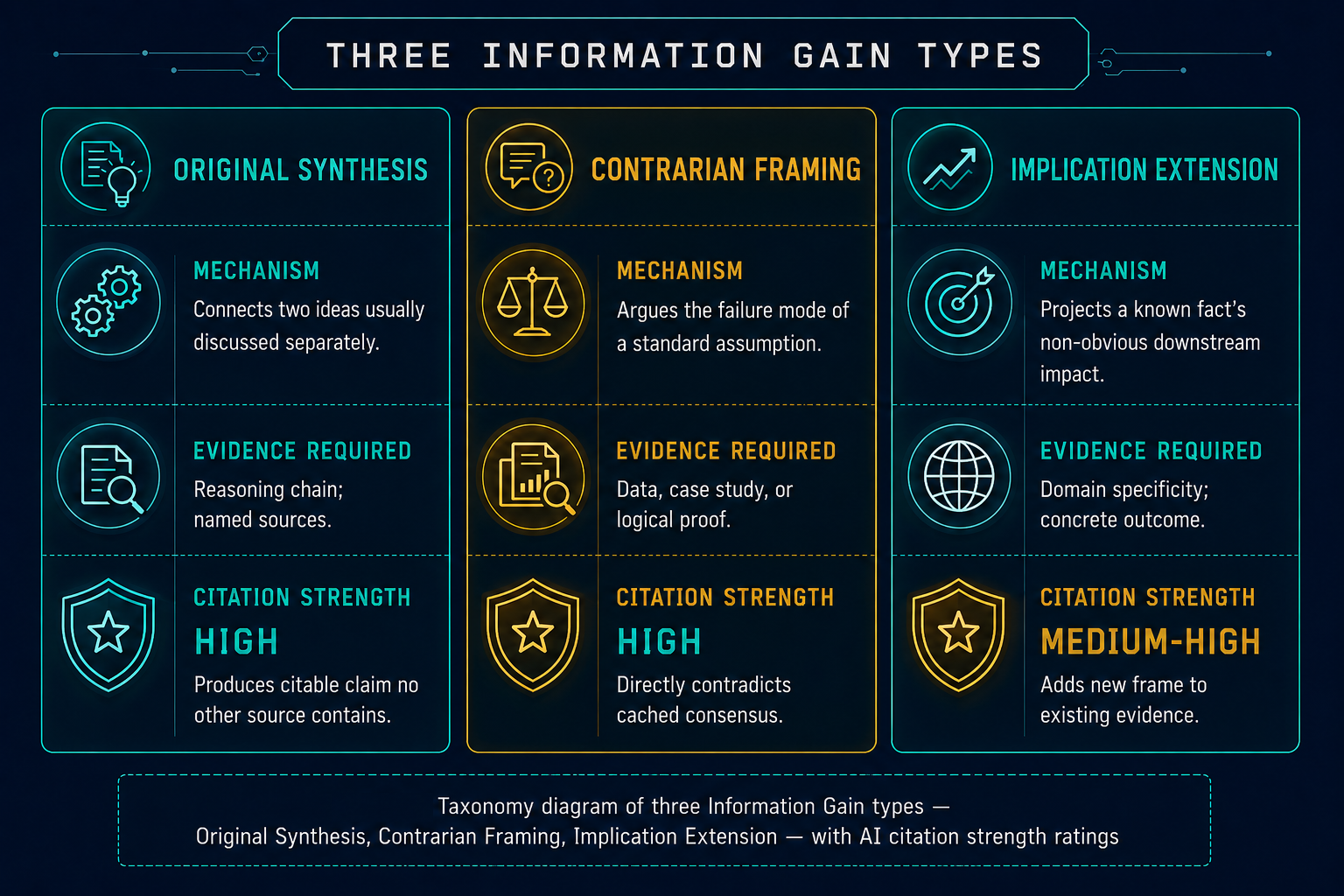
Information Gain takes three forms within the Citation Architecture. Each has a different mechanism and evidence requirement.
| Information Gain Type | Mechanism | Evidence Required | AI Citation Strength |
|---|---|---|---|
| Original Synthesis | Connects two ideas usually discussed separately | Reasoning chain; named sources | High — produces citable claim no other source contains |
| Contrarian Framing | Argues the failure mode of a standard assumption | Data, case study, or logical proof | High — directly contradicts cached consensus |
| Implication Extension | Projects a known fact’s non-obvious downstream impact | Domain specificity; concrete outcome | Medium-High — adds new frame to existing evidence |
Original Synthesis produces the highest-ceiling claims. It connects two ideas not currently connected in published discourse — the connection itself is the original contribution. Neither underlying idea needs to be new. Example: arguing that citation decay (a publishing concept) and customer churn (a product concept) follow identical mathematical curves and should be managed with the same retention logic.
Contrarian Framing targets cached consensus — the standard industry answer that AI systems have absorbed into training data. It does not contradict for effect. It identifies the specific scenario, failure condition, or audience where the standard answer breaks down, and argues it with evidence. This article is a live example: the claim that writing quality is not a primary AI retrieval signal directly contradicts how most content agencies position their services. The Aggarwal et al. [2024] finding is its evidence.
Implication Extension takes a documented finding and projects its consequence for a specific audience the original finding did not address. A 2024 study finds X. The article argues what X means for SaaS brands at $1M–$10M ARR specifically. The study is not original. The implication for that niche is. This is the most accessible type for clients without proprietary data.
All three produce content that AI systems can excerpt without duplicating what is already cited from competing sources. That is the operational definition of Information Gain for AI citation purposes.
How to Audit Your Existing Content for Zero Information Gain
Zero Information Gain content is not bad content. It is content that restates existing consensus with no new claim, no new frame, and no new implication. Run this audit on highest-traffic articles before the next publication cycle.
1. Identify the central claim. What is the one thing this article argues that a reader could not get from the top three competing articles? If it cannot be stated in one sentence, the article has zero Information Gain.
2. Test the claim against competitor content. Search the primary keyword. Read the top five results. If the central claim appears in substance in any of them, the article is restating consensus. Modify the claim — not by making it more thorough, but by making it more specific, more contrarian, or connected to a frame outside the topic’s normal boundaries.
3. Check for an Information Gain type. Is the claim an Original Synthesis, a Contrarian Framing, or an Implication Extension? If none of the three apply, add one before publishing.
4. Verify evidence proximity. Per the RAG Claim-Evidence Proximity Rule, evidence supporting the claim must appear within the same paragraph as the claim or in the immediately following paragraph. Evidence more than two paragraphs away is functionally invisible to RAG retrieval systems during extraction.
5. Flag for update or archive. Articles with zero Information Gain and low traffic: archive or redirect. Articles with zero Information Gain and high traffic: update with one of the three Information Gain types — not a quality rewrite, but a novel claim added with proximate evidence.
This audit belongs in a content maintenance calendar, not just initial production. Citation Half-Life — the rate at which citation probability decays as competing content accumulates — means that an article with strong Information Gain today may lose its differentiation within 90–180 days. When the claim that differentiated an article appears in three or more competing URLs, the Information Gain has expired. Update before citation velocity drops.
Frequently Asked Questions About Information Gain for AI Citations
Understanding Information Gain
What is Information Gain in content marketing?
Information Gain in content marketing is the measurable difference between what content contributes to a topic and what existing content already covers. In the context of AI Citation Engineering, it specifically refers to whether an article contains a claim, frame, or implication that no competing URL in the retrieved corpus already contains. Content with high Information Gain is more likely to be cited by AI systems — Perplexity, ChatGPT, Google AI Overviews — because it adds something to the synthesized answer rather than duplicating what other cited sources already cover. It is the primary signal in the Compounding Layer of the Citation Architecture.
Why doesn’t well-written content get cited by AI systems?
Writing quality controls user experience after retrieval — it does not control whether retrieval happens. AI retrieval systems score content on semantic relevance, entity density, freshness, and novelty of claim. A well-written article that restates existing consensus is semantically similar to multiple other documents in the corpus. When multiple documents say the same thing, the AI system has no reason to cite more than one. The well-written article competes against equally well-written articles and loses on novelty. The fix is not better prose — it is a distinct claim that no competing source contains.
How do I generate Information Gain if my client has no original research?
Three mechanisms work without proprietary data. First, Original Synthesis: connect two ideas discussed separately in the discourse and argue the connection explicitly — the combination is the original contribution. Second, Contrarian Framing: identify the standard industry answer to a question and argue the specific scenario where it fails, supported by logic or accessible third-party evidence. Third, Implication Extension: take a documented finding and project its consequence for a specific niche the original finding did not address. All three produce citable claims without requiring proprietary data or in-house research.
Managing Information Gain Over Time
How often does Information Gain expire?
Information Gain is not permanent. As competitors respond to claims — restating, expanding, or countering them — the novelty of the original contribution erodes. This is Citation Half-Life: the rate at which citation probability decays as the corpus catches up to an original claim. For fast-moving topics (AI, regulation, software), Information Gain may decay within 60–90 days. For stable topics, it may hold for 12–18 months. Monitor competitor content on primary keywords every 90 days. When the differentiating claim appears in three or more competing URLs, the Information Gain has expired. Update with a new Information Gain type before citation velocity drops.
Does this mean I should stop optimizing for content quality?
No. Quality is the entry condition — it gets content indexed, read, and shared, which feeds the freshness and authority signals of the Citation Architecture’s retrieval layer. The argument is not that quality is irrelevant. It is that quality alone is insufficient for AI citation, and most content teams invest the large majority of their effort in quality optimization while investing near zero in Information Gain generation. The rebalancing is not away from quality — it is toward adding a deliberate Information Gain identification step before the quality pass begins. Identify the claim first. Then write it well.
The Information Gain problem is not a writing problem. It is a thinking problem — specifically, whether the brief includes a concrete answer to “what does this article contribute that the existing corpus does not contain?” If the brief cannot answer that in one sentence, the article should not enter production.
Information Gain is the accumulation layer. But before any content can be cited, the retrieval prerequisite must be met: AI systems must be able to resolve your brand as a verified entity. That infrastructure is the Entity Spine — why AI engines don’t know your brand exists.
Find out which Citation Architecture signals your content is missing.
Run Free Check →