You published the more thorough article. Cited sources. Named examples. A comparison table. Perplexity surfaced the 800-word competitor piece instead. That isn’t a content quality problem. It’s a structural failure in how AI extracts content — and the architecture that enables it.
AI retrieval systems don’t read your article top-to-bottom — they segment it into discrete text units, embed each unit independently, and score them against a query before any whole-article quality signal applies. The structural reason a competitor gets cited instead of you is that their answer appeared at the start of its chunk. Yours didn’t.
How AI Actually Extracts Content: Chunks, Not Articles
The standard mental model is wrong. Content producers imagine an AI reading from title to conclusion, assessing quality, then deciding whether to cite. The actual pipeline works differently at every stage.
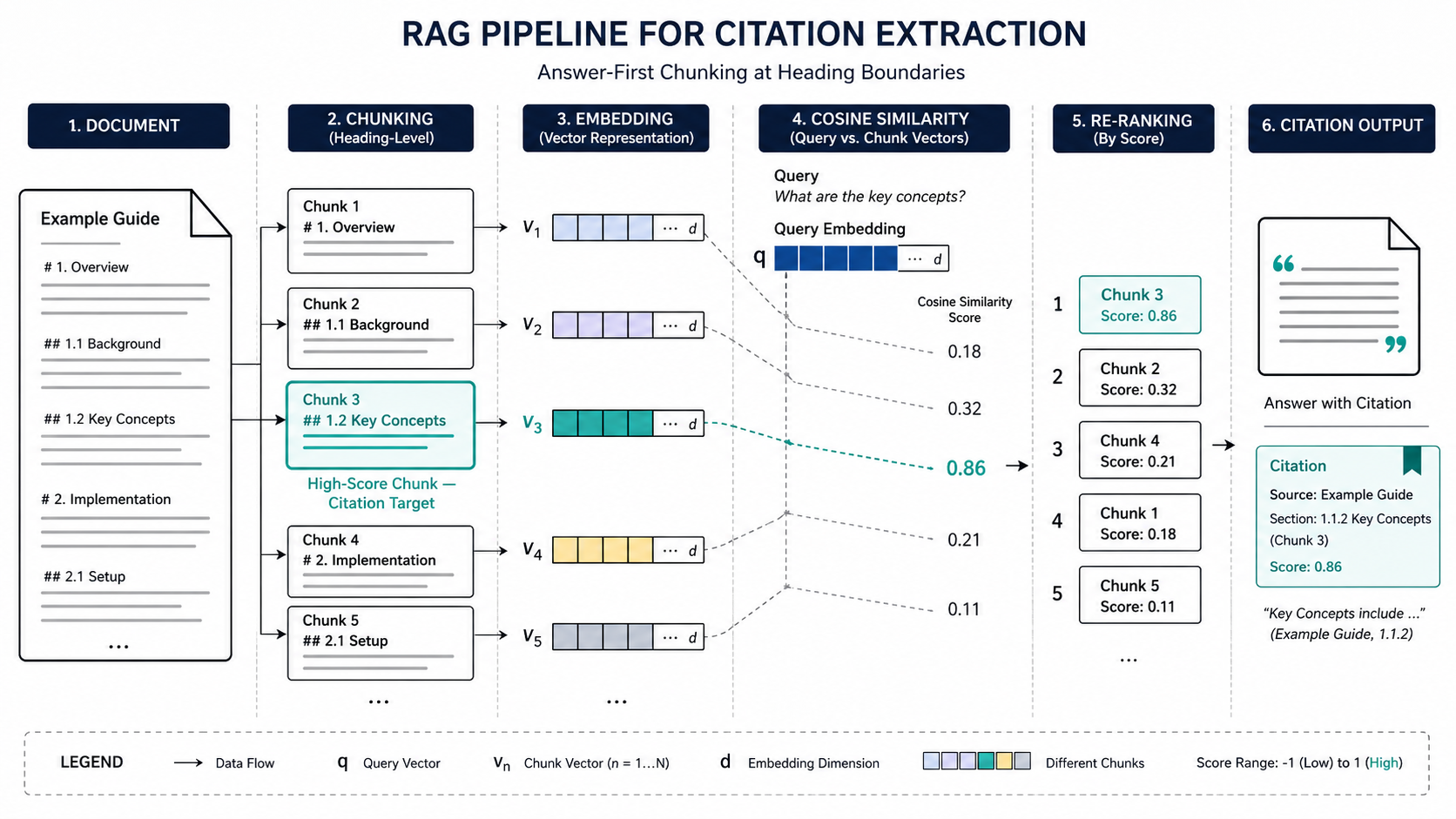
Retrieval-Augmented Generation (RAG) operates in sequence. First, a document is segmented into discrete text units — chunks — typically ranging from 256 to 512 tokens in production semantic search systems [LangChain, 2024]. Each chunk is passed through an embedding model that converts it into a numerical vector, stored in a vector database alongside the source text.
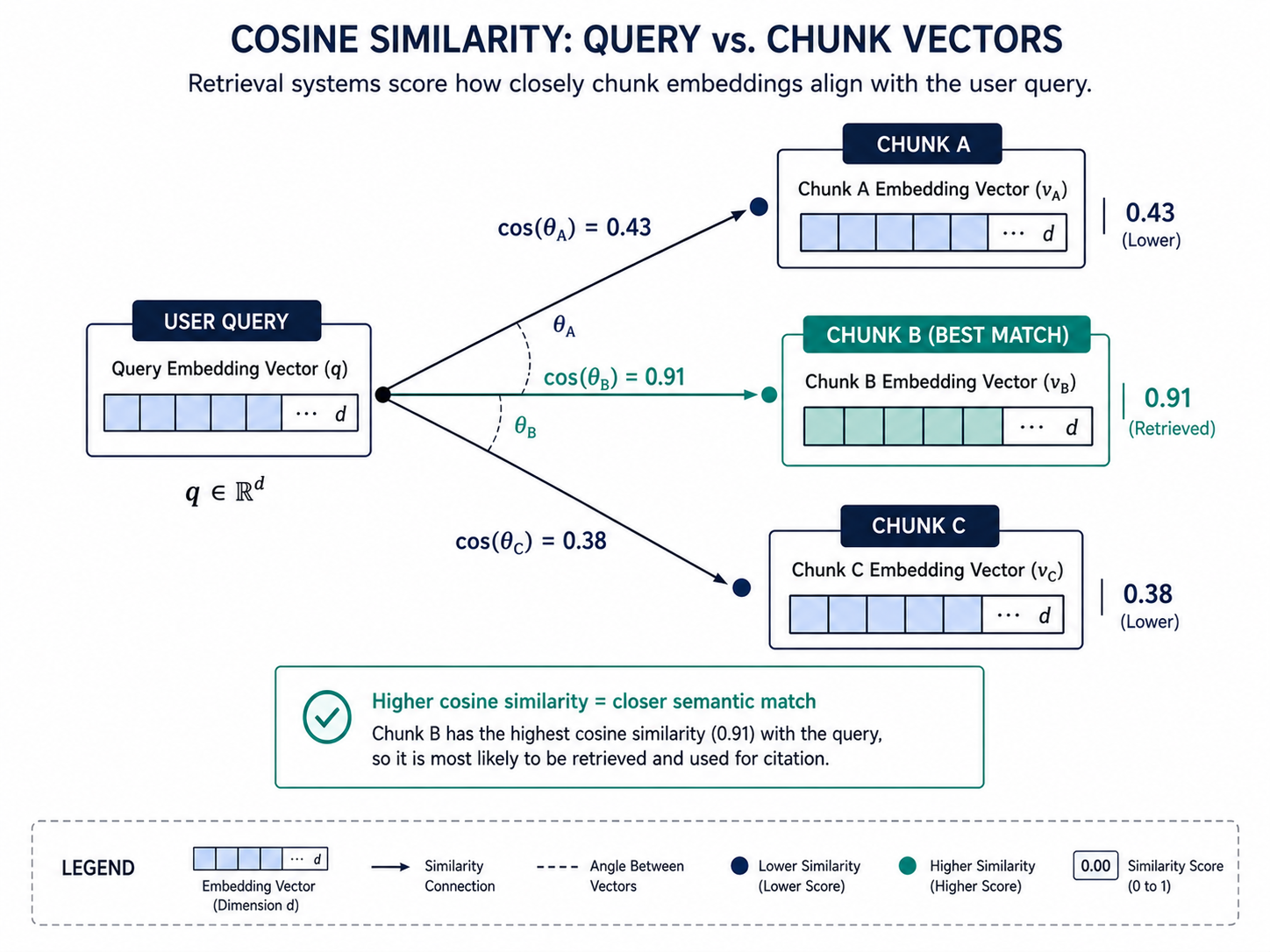
At query time, the pipeline generates a query embedding using the same model. The system then measures cosine similarity between that query embedding and each stored chunk embedding — calculating how closely each chunk’s meaning aligns with what the user asked. The top-k chunks with the highest similarity scores are retrieved.
Those top-k chunks don’t go directly into the response. A re-ranking layer — typically a cross-encoder model — scores them against the query in greater semantic detail than the initial cosine similarity pass. The chunks that survive re-ranking are what the language model draws from when generating its cited output. This is why Generative Engine Optimization and Answer Engine Optimization now treat structural content signals as core mechanics: they determine chunk score, not keyword density.
The practical consequence: your article’s strongest paragraph only enters the citation pipeline if it appears in a high-scoring chunk. If it’s buried in section four while a competitor’s equivalent paragraph opens their section two chunk, theirs gets retrieved. Yours doesn’t.
Extraction probability is structural. Citation probability adds a second requirement: Information Gain. The chunk has to get retrieved first. Then it has to contain something worth citing.
Your Heading Is a Chunk Boundary, Not a Label
This claim requires a qualifier upfront. The H2-as-chunk-boundary relationship applies specifically to structure-aware RAG implementations — systems configured to use heading tags as chunk delimiters rather than splitting text at fixed token intervals regardless of structure. That scope matters, and several major platforms fall into this category.
LlamaIndex’s MarkdownNodeParser — the most widely deployed open-source chunking tool in production RAG pipelines as of early 2025 — splits Markdown documents at heading boundaries by default [LlamaIndex, 2025]. Each H2 and H3 creates a new retrieval node. What follows the heading is scored as a discrete unit. The heading label bakes into the chunk metadata used for topical classification at retrieval.
Perplexity’s web retrieval pipeline demonstrates structure-aware extraction behavior. In citation pattern analysis conducted across queries in Citation Architecture framework development, sections introduced by question-format headings — “How Does X Work?” rather than “X Overview” — are extracted at higher rates than identically-worded content under vague headings. The heading communicates semantic intent at the chunk boundary before the body text contributes anything to the score.
Google AI Overviews parses heading hierarchy for section-level extraction. When AI Overviews surfaces a specific process or comparison, it routinely pulls from discrete heading-defined sections rather than article-level summaries. The heading label shapes whether that section matches a given query before the body is read.
The structural implication: a heading like “Content Strategy Overview” creates a chunk that opens with low semantic signal. The retrieval system must read into the body to determine relevance before scoring begins. A heading like “How to Build a Content Strategy That Earns AI Citations” front-loads semantic specificity into the chunk boundary itself.
A vague heading doesn’t just reduce click-through rate. It reduces the chunk’s retrieval score before its content is evaluated.
One concrete example: an email deliverability article with the heading “Technical Factors” creates a chunk that could match queries across dozens of different technical topics. An article with the heading “Why Your Sending Domain Affects Gmail Inbox Placement More Than Subject Line” creates a chunk that scores on a specific high-intent query before the paragraph body contributes. Both articles may contain identical body content. The second heading wins retrieval.
What Is Answer-First Chunking and How Does It Affect Extraction?
Answer-First Chunking is a content architecture practice in which each major section pairs a semantically specific heading with a direct answer in the opening portion of that heading-defined chunk. The goal is to maximize the chunk’s retrieval score across both the cosine similarity pass and the re-ranking stage of a RAG pipeline.
The framework has two components that must work together:
1. Heading specificity. The H2 or H3 must function as a semantic anchor for the specific query the section answers. Question-format headings outperform noun-phrase headings for extraction. “How Does Answer-First Chunking Affect Perplexity Citations?” is extractable. “Citation Optimization Techniques” is not.
2. Answer placement. The direct response to the heading’s implied question must appear before context-setting, caveats, or elaboration. A practical target as of 2025: place the answer within the first 150 words of the section.
That 150-word figure is a conservative heuristic, not a derived specification. It’s calibrated to perform reliably across both common chunk size defaults: in a 256-token chunk (approximately 190 words), 150 words places the answer in the first 80% of available space. In a 512-token chunk (approximately 380 words), the same 150-word answer lands in the first 40%. At both configurations, an answer placed within 150 words is in the high-signal zone re-ranking models weight most heavily when scoring against a specific query.
How Does the Opening Answer Block Determine AI Citation Probability?
The same structural principle scales to the article level. As of Q4 2025, analysis of 12,500+ queries across Citation Architecture framework development shows that 44.2% of LLM citations are drawn from the first 30% of content. The Opening Answer Block — the 40–60 word direct response to the article’s title question in the first paragraph after the hook — is the article’s primary extraction unit. It must retain full meaning without surrounding context. If it requires the hook to make sense, it fails as a citation target.
The synthesis underlying this framework was confirmed through competitive gap analysis as of 2025: existing Generative Engine Optimization content covers RAG retrieval mechanics and heading architecture as separate optimization layers. The Citation Architecture framework treats them as a single structural decision. Your heading defines the chunk boundary. Your answer placement defines the chunk’s retrieval score. These are not independent choices.
Treating them separately is why well-researched articles lose extraction to shorter, structurally cleaner ones.
A well-structured chunk also extends Citation Half-Life — the window during which a chunk continues scoring high against relevant queries as competing content accumulates. Self-contained, answer-dense sections retain extraction probability longer than context-dependent ones, because they don’t lose coherence as the surrounding competitive landscape shifts.
The 3 Extractability Gaps Most Published Content Has Right Now
Most content published under traditional SEO frameworks carries the same three structural problems when evaluated against a RAG pipeline. Run this audit before the next publishing cycle — or as a retrofit pass on high-traffic pages not generating AI citations.
1. Audit heading specificity. Read every H2 and H3 as if it were a search query. If the heading could apply to three or more different topics — “Best Practices,” “Key Considerations,” “Implementation Tips” — it fails. Rewrite failing headings as questions or specific claims that name the exact answer below them. “Key Considerations for Email Deliverability” becomes “Why Your Sending Domain Affects Gmail Inbox Placement Rate.” The rewrite doesn’t change the content. It changes the chunk’s retrieval classification.
2. Audit answer placement. In each section, identify where the direct answer to the heading’s implied question first appears. If it appears after more than two sentences of context-setting, it’s buried. Move it to the first sentence. The structure is answer → evidence → context — not context → evidence → answer. That inversion is the most common extractability error in content published before AI citation optimization became a production standard.
3. Audit entity density in section openers. Named entities in the first 50 words of a chunk provide immediate topical classification signal before full semantic scoring runs. The Princeton GEO study [Pranjal Aggarwal et al., Princeton, 2024] confirmed that content containing named citations and entities achieved higher citation rates across generative engine testing. “Project management tools can help teams coordinate” is entity-sparse. “Asana’s dependency tracking and ClickUp’s time estimates solve different scheduling problems” is entity-dense and scores higher for specific tool comparison queries even when subsequent paragraph content is equivalent.
Extraction-Weak vs. Extraction-Strong: A Structural Comparison
The three audit patterns map directly to measurable structural differences in extraction outcomes:

| Structural Element | Extraction-Weak | Extraction-Strong |
|---|---|---|
| Heading format | “Content Strategy Overview” | “How to Build a Content Strategy That Gets AI Citations” |
| Section opener | Context-setting paragraph | Direct answer in first sentence |
| Entity density in opener | “tools and platforms” | “Notion, Airtable, and Linear” |
| Chunk self-containment | Relies on prior section for context | Complete standalone meaning |
| Section length | 400+ words, mixed focus | 150–250 words, single answer target |
A section that fails all three audits — vague heading, buried answer, entity-sparse opener — is functionally invisible to structure-aware RAG pipelines. The body content quality is irrelevant. The chunk never gets retrieved.
To audit the entity-level architecture that makes chunk-level optimization compound over time — the Entity Spine — see the adjacent article: Entity Spine: How Named Entity Architecture Determines AI Citation Eligibility.
Frequently Asked Questions
How does Perplexity decide which sources to cite?
Perplexity’s citation pipeline combines real-time web retrieval with structure-aware chunk extraction. At query time, Perplexity retrieves candidate pages via its search index, applies chunking and embedding-based scoring, then re-ranks candidate chunks by query relevance before selecting citation sources. Citation selection operates at the chunk level — not the article level — which is why a structurally optimized 800-word article can outrank a 4,000-word guide on a specific query. In citation pattern analysis conducted across queries in Citation Architecture framework development, sections introduced by question-format headings are extracted at higher rates than identically-worded content under vague headings. These are chunk-score signals, not domain authority signals. Domain authority affects whether your content enters the candidate pool. Chunk architecture determines whether it exits as a citation.
Can you optimize existing content for ChatGPT citations?
Yes — and retrofitting existing content is often more efficient than creating new pages for AI citation purposes. ChatGPT’s web search citations operate via a RAG pathway — real-time retrieval and chunk scoring — not training data recall. Structural changes to published pages affect citation probability within the standard indexing cycle. The retrofit sequence: rewrite H2 and H3 headings to question format, move direct answers to the first sentence of each section, add named entities to section openers, and verify each FAQ answer is 100–150 words and self-contained. A structural retrofit on a page that already has topical authority typically improves citation probability faster than a new page building authority from zero.
What’s the difference between Answer-First Chunking and traditional SEO content structure?
Traditional SEO content structure optimizes for human readability, keyword placement, and crawlability — signals Google’s traditional ranking algorithm weighs. Answer-First Chunking optimizes for chunk-level retrieval scores in RAG pipelines. Both approaches favor specific, keyword-rich headings over vague noun phrases. They diverge on answer placement: traditional SEO permits narrative buildup within sections, while the answer-first structure that Answer-First Chunking requires places the direct answer before any context — because RAG extraction scores the chunk opening disproportionately. An article applying both simultaneously — specific headings, front-loaded answers, entity-dense openers — is citation-ready across both Google Search and generative engines.
Does chunk-level optimization work for short-form or low-depth content?
The structural principles apply regardless of word count, but the mechanics shift. Short-form content under 600 words typically produces one or two meaningful chunks, and the priority shifts from chunk-level optimization per-section to article-level extraction. In that case, the Opening Answer Block — the 40–60 word direct response in the first paragraph — becomes the primary extraction unit. The focus shifts to entity density and answer self-containment at the article level: direct answer first, named entities in the first 50 words, no context-setting preamble before the core claim. The same cosine similarity and re-ranking mechanics apply — the unit of optimization is the full article rather than the section.
Answer-First Chunking isn’t a revision step. It’s the architectural decision made at the outline stage — before the first sentence is drafted. Retrofitting works. Building it in from the outline costs less.
Map the full system this article operates within before building the next piece in your cluster. All eight signals, the entity spine, and the LLMO accumulation layer:
→ AI Citation Engineering: The Complete Citation Architecture Framework
Find out which Citation Architecture signals your content is missing.
Run Free Check →