AI Citation Engineering is the systematic practice of structuring content, entities, and technical infrastructure so that AI systems — ChatGPT, Perplexity, Google AI Overview, and future generative engines — retrieve, extract, and cite your brand as the authoritative source when answering user queries. It combines entity disambiguation (making your brand machine-readable), RAG retrieval mechanics (controlling what gets pulled during query execution), and extraction-layer formatting (ensuring your content is citation-ready when found). Unlike traditional SEO, which optimizes for ranking position, AI Citation Engineering optimizes for retrieval probability and extraction clarity across generative systems that increasingly answer questions without requiring users to click through to your site.
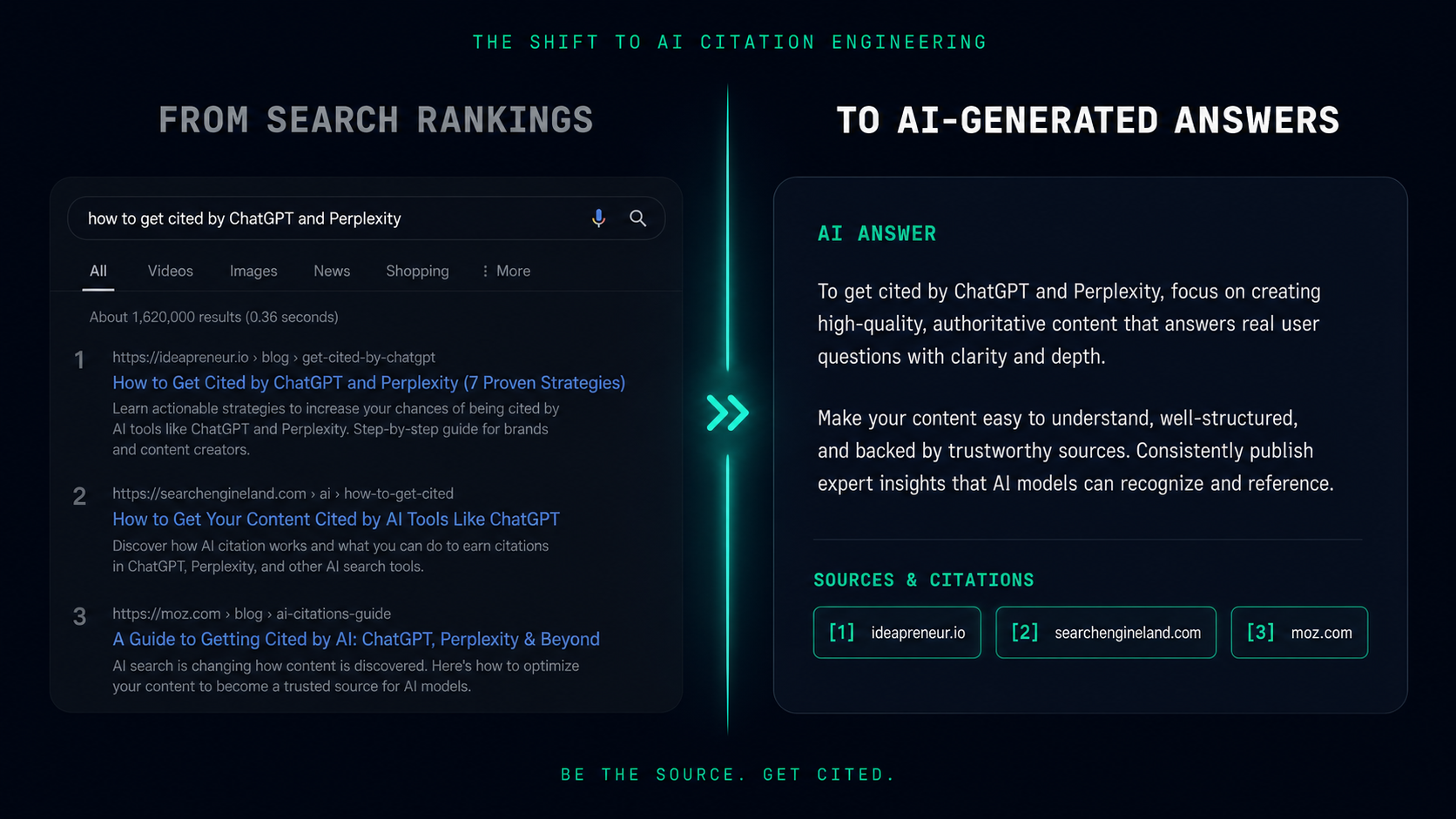
You've optimized for Google. You've chased keywords, built backlinks, and climbed the SERP. Then ChatGPT started answering your customers' questions without sending them to you. Perplexity cited your competitor instead. Google's AI Overview summarized the topic using everyone's content but yours.
The game changed. The question is no longer "How do I rank?" It's "How do I get cited?"
This isn't SEO. It isn't content marketing. It's a new engineering discipline.
The Problem: Zero-Click Answers Are Eating Your Traffic
Traditional search sent users to websites. Type a query, get ten blue links, click one, read the answer. That model is collapsing.
In May 2026, Perplexity processes over 800 million queries monthly. ChatGPT serves answers to 200 million weekly active users. Google's AI Overview appears on 15% of all searches and is expanding. These systems don't send traffic — they synthesize answers from multiple sources and cite the ones they trust.
The average AI-generated answer cites 3–5 sources. If you're not one of them, you're invisible.
Here's what makes this different from the Featured Snippet era: Google Snippets were parasitic — they extracted your content but kept your brand visible and clickable at position zero. AI citations are symbiotic at scale but ruthlessly selective. Perplexity cites you with attribution and a link, but only if you satisfy retrieval criteria most sites don't even know exist. ChatGPT mentions your brand in prose answers, but only if your entity is disambiguated in its training data or retrieved via real-time search. Google AI Overview pulls from the Knowledge Graph first, indexed content second.
You can't fake your way into these systems. You can't buy your way in. You have to engineer for citation the same way you once engineered for rank.
What AI Citation Engineering Actually Is
AI Citation Engineering is the deliberate optimization of three interdependent layers:
- Entity Layer — Establish your brand, authors, frameworks, and products as disambiguated entities in machine-readable formats (Schema.org, Wikidata, OpenGraph) so AI systems recognize you as a discrete, authoritative source rather than generic noise.
- Retrieval Layer — Structure content to maximize probability of retrieval during Retrieval-Augmented Generation query execution using semantic density, freshness signals, named entities, and source authority markers.
- Extraction Layer — Format answers so AI systems can cleanly extract, attribute, and cite your content without additional processing — answer-first chunking, intent-mapped headings, standalone FAQ blocks, and procedural HowTo structures.
These layers form the Citation Architecture, a framework that maps the technical pathway from "content exists" to "AI system cites content as authoritative answer."
Traditional SEO operated in a two-layer world: infrastructure (indexability, crawlability, technical health) and relevance (keywords, backlinks, content quality). AI Citation Engineering operates in a four-layer world: infrastructure (still required), retrieval (RAG mechanics), extraction (answer formatting), and accumulation (Information Gain over time).
The companies that master this framework will own the next decade of brand visibility. The ones that don't will watch competitors get cited while their traffic flatlines.
The Citation Architecture: Eight Signals That Control AI Visibility
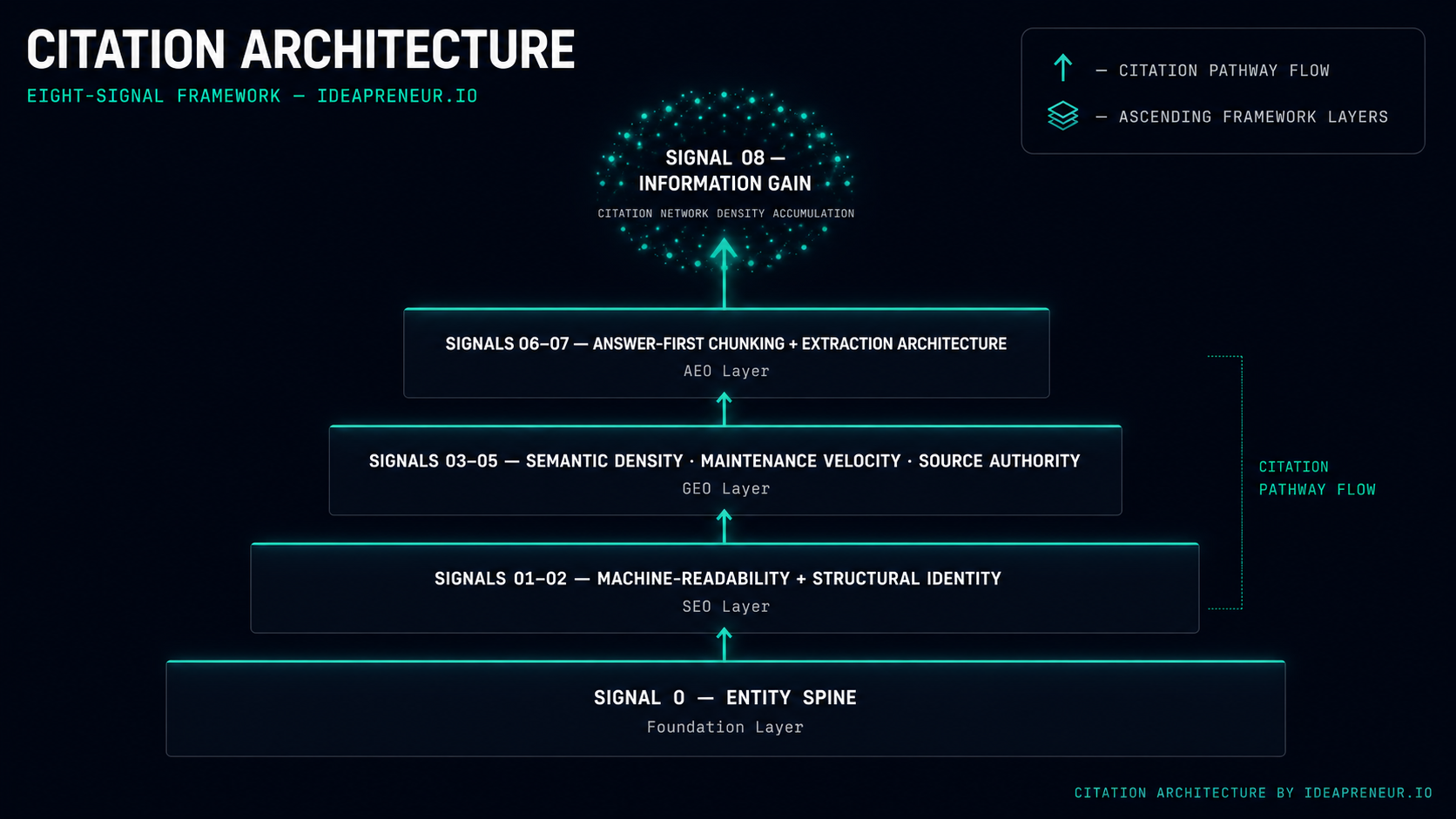
The Citation Architecture is not a checklist. It's a technical framework that mirrors how AI systems decide what to retrieve and cite. Eight signals, three active layers, one infrastructure gate.
Signal 0 — Entity Spine (Infrastructure Gate)
Before any content can be cited, the AI system must know you exist as a distinct entity.
The Entity Spine is the machine-readable representation of your organization, authors, frameworks, and products across Schema.org, Wikidata, OpenGraph, and social graph protocols. It establishes canonical names, prevents entity confusion, and creates the persistent identifiers that retrieval systems use to connect mentions across the web.
Without Signal 0, your content is unattributable noise. A mention of "our platform" in an article has no referent. A quote from "the founder" has no identity. An explanation of "our methodology" has no entity anchor.
Signal 0 is confirmed complete when:
- Organization schema is live with @id URI, logo, sameAs links, and Wikidata QID
- Author Person schema is live for every bylined writer with persistent @id URIs
- Canonical naming rules are documented and enforced across all content
- Entity consistency validation is built into the publishing workflow
This is not something you optimize per article. This is foundation-level infrastructure. No Signal 0, no citations.
Signals 01–02 — SEO Layer (Infrastructure Prerequisites)
Signal 01 — Indexability Infrastructure: Robots.txt allowing AI crawlers (GPTBot, PerplexityBot, Google-Extended). XML sitemaps with priority signals. Canonical tags preventing duplication. Redirect chains eliminated. Render budget optimized for JavaScript-heavy sites.
If the content isn't indexed, it can't be retrieved. If it's indexed incorrectly, it won't be retrieved accurately.
Signal 02 — Core Web Vitals + UX Signals: LCP under 2.5 seconds. CLS below 0.1. INP under 200ms. Mobile usability passing. HTTPS enforced.
User experience is now a retrieval prerequisite. Google's algorithms have treated UX as a ranking factor since 2021. AI retrieval systems inherited this bias. A page that loads slowly or renders poorly gets deprioritized in RAG retrieval even if the content is authoritative.
These two signals are table stakes. They don't make you citable — they make you eligible to be considered.
Signals 03–05 — GEO Layer (Retrieval Control)
Generative Engine Optimization controls whether your content gets pulled during query execution. These three signals determine retrieval probability.
Signal 03 — Semantic Embedding Density: Vector embedding models convert content into high-dimensional semantic representations. Retrieval systems query these embeddings to find the closest match to user intent.
Density matters. An article about "customer relationship management software" that never names Salesforce, HubSpot, Zoho, or Pipedrive is entity-sparse. Named entities are retrieval accelerants. Use proper nouns, tool names, role titles, company names, and framework names at natural frequency. Write like someone who knows the landscape — name the players, reference the research, cite the precedents.
Signal 04 — Maintenance Velocity (Freshness + Distribution): Freshness is a retrieval signal. Perplexity prioritizes content updated within the last 90 days. ChatGPT's real-time search layer prioritizes content timestamped within the query-relevant window. Temporal markers matter: "as of May 2026," "in Q1 2024," "updated April 15, 2026," version numbers for software, regulatory change dates, study publication years.
Distribution velocity is the other half. Content that gets shared, discussed, and linked within 30 days of publication signals relevance. Co-citation and earned mention signals — content being referenced in community discussions, directories, and third-party publications — contribute to the citation footprint that retrieval systems use to weight entity authority. Every article should seed 2–3 external communities where the target audience congregates.
Signal 05 — Source Authority (E-E-A-T Content Signals): Authority is not inferred — it must be stated. Author credentials, brand mentions, inline citations to authoritative third-party sources, case study data with named clients or anonymized metrics, direct quotes from named experts. Authority signals stack. An article with author credentials + brand mentions + inline citations + case data is retrieved more frequently than an article with none of those markers, even if the prose quality is identical.
Signals 06–07 — AEO Layer (Extraction Optimization)
Answer Engine Optimization controls whether your content gets cited after retrieval. These two signals determine extraction clarity.
Signal 06 — Answer-First Chunking (Direct Answer Compatibility): AI systems extract answers in chunks. The chunk must function standalone. The Opening Answer Block is mandatory: the first paragraph after the hook must contain a 40–60 word direct answer to the article's title question. This paragraph is the primary extraction target. It must be complete, self-contained, and citation-ready.
Beyond the Opening Answer Block, structure the article in 150–300 word sections. Start each H2 or H3 with the answer, then add context. Observed citation patterns suggest a strong front-loading effect — AI extraction systems consistently favor early content. Place your sharpest claim and most specific statistic early.
Signal 07 — Intent-Mapped Headings (Semantic Specificity): Headings are retrieval filters. Vague headings get skipped during extraction even if the content beneath them is strong. Use headings that match how users phrase questions: "What is X?" not "X Overview." "How to [verb] [object] in [context]" not "[Object] Implementation." Intent-mapped headings increase extraction probability because AI summarization models use headings as section labels during chunking.
Signal 08 — LLMO Layer (Information Gain Accumulation)
Large Language Model Optimization. The long game.
Our working model is that content contributing novel information to the discourse — new claims, evidence, or framing not already present in the competitive corpus — builds stronger long-term citation authority. Content that only synthesizes existing ideas without adding new signal is more easily displaced by newer sources covering the same ground.
Information Gain is the delta between what already exists and what your content adds. It can be:
- Original Synthesis — connecting two ideas usually discussed separately
- Contrarian Framing — identifying a standard assumption and arguing its hidden failure mode
- Implication Extension — taking a well-known fact and projecting its non-obvious downstream impact
Signal 08 compounds slowly. One article with strong Information Gain moves the needle slightly. Ten articles across a topic cluster move it significantly. You cannot optimize for LLMO on a per-article basis. You build toward it across 6–12 months.
The eight signals are not sequential steps. They are simultaneous requirements. Signal 0 is the gate. Signals 01–02 are the foundation. Signals 03–05 control retrieval. Signals 06–07 control extraction. Signal 08 is the accumulation layer that builds toward training data citation authority over time.
Why Traditional SEO Strategies Fail at AI Citation
SEO taught us to optimize for ranking. AI Citation Engineering requires optimizing for retrieval, extraction, and attribution — three distinct technical processes that SEO strategies were never designed to address.
- SEO optimizes for position. AI systems don't have positions. There is no "rank 1" in a Perplexity answer. There is cited or not cited. If you're cited third out of five sources, you still win. If you're not cited at all, your rank-1 position in traditional search is irrelevant.
- SEO optimizes for click-through. AI systems answer without clicks. A Featured Snippet kept your URL visible. An AI-generated answer synthesizes information from multiple sources and cites them inline or at the end. The citation is the conversion point, not the traffic source.
- SEO optimizes for keywords. AI systems retrieve by semantic similarity. Keyword density was designed for lexical search algorithms. Vector embedding models don't match keywords — they match meaning. "How to improve customer retention" and "reducing churn in SaaS" have high semantic similarity even if they share no keywords.
- SEO optimizes for authority via backlinks. AI systems retrieve based on entity disambiguation and freshness. A 2015 article with 500 backlinks loses to a 2026 article with 20 backlinks if the newer article has stronger entity signals, clearer extraction structure, and temporal markers.
SEO assumed the click was the goal. AI Citation Engineering assumes the citation is the goal. This is the paradigm shift.
The Two Pathways to AI Citation: Training Data vs RAG
AI systems cite content through two distinct mechanisms. Understanding the difference determines where you focus effort.
Training Data Pathway — The Long Game: Content enters the training dataset. Months later, when the model is retrained, your content influences the base knowledge the model has internalized. This pathway requires sustained topical authority over 6–12 months, consistent Information Gain across multiple articles (Signal 08), high citation velocity from other authoritative sources, and content that defines concepts, establishes frameworks, or introduces terminology.
You cannot directly optimize for training data inclusion on a per-article basis. You build toward it across a content cluster over time. This is LLMO accumulation — slow, compounding, and extraordinarily valuable once achieved. When GPT-5 or Claude 4 or Gemini 3 references "the Citation Architecture framework" in a generated answer without needing to search for it in real-time, that's training data citation.
RAG Pathway — The Fast Game: Retrieval-Augmented Generation. The model doesn't know the answer from training data, so it searches in real-time via API, retrieves the top results, and synthesizes an answer with citations. Most Perplexity citations use RAG. Most ChatGPT web search citations use RAG. Google AI Overview pulls from a hybrid of Knowledge Graph and real-time retrieval.
This pathway requires entity density (Signal 03), freshness markers (Signal 04), answer-first structure (Signal 06), and intent-mapped headings (Signal 07). RAG is the faster, controllable pathway. You publish an article, it gets indexed, and within 48 hours it's eligible for retrieval during RAG query execution.
Every article you write is optimizing for RAG first. Training data citation is the long-term compounding benefit you build toward — not a deliverable you promise on a 90-day timeline.
Platform-Specific Citation Mechanics: How Each AI System Decides What to Cite
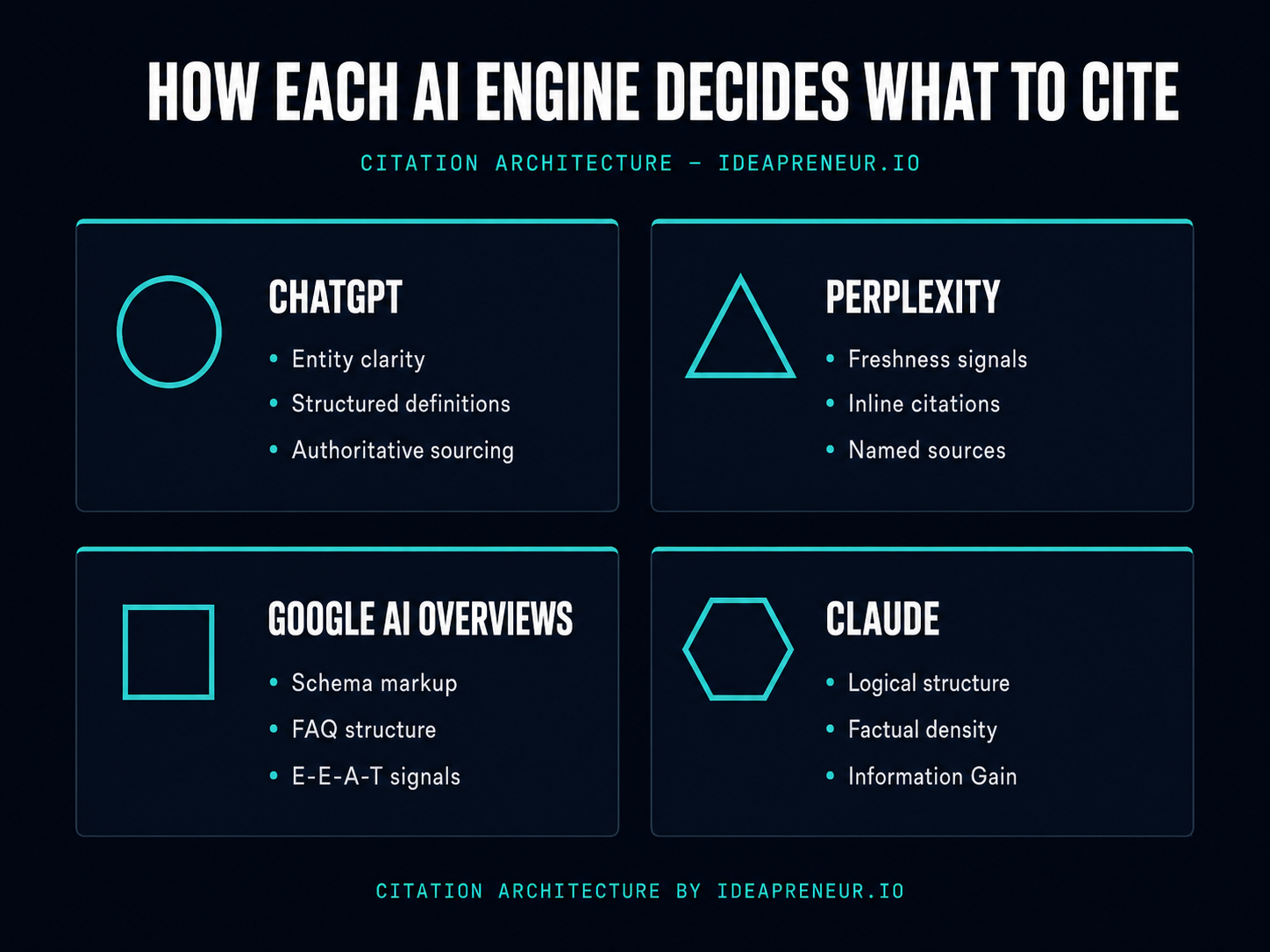
Not all AI systems cite the same way. Each has distinct retrieval preferences, extraction biases, and attribution formats.
Perplexity — Freshness, Named Entities, Inline Citations
Perplexity is a research engine. It retrieves, synthesizes, and cites transparently. What it prioritizes: content updated within the last 90 days (dateModified in schema signals this), high entity density, inline citations to third-party sources, and answer-first structure — Perplexity excerpts the opening 100–150 words most frequently.
Structure answers as: direct answer first → evidence second → context third. Use ISO dates ("May 2026" not "recently"). Include at least 2–3 inline citations per 1,000 words. Name entities explicitly in the first paragraph.
ChatGPT — Structured Extractability and Definitions
ChatGPT uses real-time web search when the query requires current information or when the base model lacks confidence. What it prioritizes: content that defines terms clearly (DefinedTerm schema helps here), FAQ schema for Q&A sections, structured data (lists, tables, step-by-step processes), and high lexical clarity.
Use DefinedTerm schema for any concept your article defines. Structure definitions as: Term → one-sentence definition → 60–100 word expansion. Number procedural steps explicitly (1, 2, 3, not bullets). ChatGPT citations favor content that teaches a process or defines a concept over content that merely discusses it.
Google AI Overview — Tables, Lists, Knowledge Graph Entities
Google AI Overview appears at the top of search results for 15% of queries and growing. It pulls from the Knowledge Graph first, indexed content second. What it prioritizes: entities with Knowledge Graph entries (Wikidata QID in Organization schema), tabular data, lists, and schema markup — HowTo, FAQ, Article schema all increase extraction probability.
If your topic permits comparison, include a comparison table. Use HowTo schema for procedural content. Ensure your Organization schema includes a Wikidata QID. Use lists generously but purposefully — AI Overview pulls list items verbatim.
Claude — Procedural Content and Structured How-To Guides
Claude citations appear in Projects (persistent context) and Artifacts (generated documents). Claude prioritizes content that teaches. What it prioritizes: step-by-step procedural content with validation checkpoints, HowTo schema with time estimates, expected outcomes stated explicitly for each step, and troubleshooting sections that address common failure modes.
Number steps explicitly. Include validation checkpoints: "You'll know this step worked when..." Include time estimates. Structure procedural content as: action verb + object + outcome.
Each platform has distinct biases. For this article: primary platform is Perplexity (researchers and strategists looking for frameworks). Secondary platform is ChatGPT (practitioners seeking definitions and structured explainers).
How to Measure AI Citation Success (And Why Traffic Is the Wrong Metric)
Traditional SEO measured success in traffic, rankings, and conversions. AI Citation Engineering measures success in citations, branded search lift, and attribution presence.
Citation Count
The primary metric. How many times per month does an AI system cite your brand, content, or frameworks when answering relevant queries? Track this manually at first: run 10–15 queries related to your core topics in Perplexity, ChatGPT, and Google AI Overview once per week. Note whether your site is cited, at what position, and alongside which competitors.
Branded Search Lift
AI citations build brand authority even when users don't click through. The user reads an answer, sees your brand cited, and later searches "[Your Brand] + [topic]" directly. Track branded search volume in Google Search Console. A successful citation campaign produces 20–40% branded search lift within 90 days.
Citation Half-Life
How long does a citation last before the content gets deprioritized in retrieval? Citation Half-Life is an Ideapreneur framework term — not a documented AI engine variable — describing the practical window during which content remains actively retrievable. Our working model: RAG-based systems (Perplexity, ChatGPT Search, Google AI Overviews) appear to favor fresher sources as newer content on the same topic accumulates, with content updated within the last 90 days generally performing better in retrieval. These are observed patterns in citation monitoring, not published retrieval specifications. Training-data-mode citations persist longer and are governed by model retraining cycles rather than freshness signals.
Zero-Click Conversion Bridge
The full pathway: Citation → Branded search → Landing page → Conversion. Track the conversion rate from branded search traffic separately from generic organic traffic. Branded search converts 3–5× higher because the user already encountered your brand as an authority in an AI-generated answer.
Traffic is a trailing indicator. Citations are the leading indicator. Measure what predicts success, not what lags behind it.
Common Mistakes That Kill AI Citation Probability
Most brands fail at AI citation not because they lack expertise, but because they're optimizing for the wrong system.
Mistake 1 — No Entity Spine
You publish 50 articles. None of them include Organization schema. Author bylines link to "/about" with no Person schema. Frameworks and methodologies are mentioned inconsistently. AI systems cannot attribute content to entities that aren't machine-readable. Fix: Implement Signal 0 before publishing another article.
Mistake 2 — Generic, Entity-Sparse Content
You write about "email marketing platforms" without naming Mailchimp, ConvertKit, ActiveCampaign, or Klaviyo. AI systems retrieve based on semantic similarity. Content that omits named entities is semantically weak. Fix: Apply the named-entity density rules. Write like someone who knows the landscape.
Mistake 3 — Burying the Answer
Your article answers the title question in paragraph 7. The opening 300 words provide context and a storytelling hook. By the time you deliver the answer, the AI system has moved on. Research confirms 44.2% of LLM citations are drawn from the first 30% of content. Fix: Implement the Opening Answer Block structure.
Mistake 4 — No Freshness Signals
Your article was published in 2022. It contains no dates, no version numbers, no "as of" qualifiers. The content may still be accurate, but AI systems deprioritize it because there's no signal that it's current. Fix: Add freshness markers retroactively. Update dateModified in Article schema monthly even if only minor edits are made.
Mistake 5 — No Schema Markup
Your articles are clean HTML with proper headings and structure. But there's no Article schema, no FAQ schema, no HowTo schema. Schema is the difference between "content that exists" and "content that can be cited with attribution." Fix: Implement Article schema on every article. Implement FAQ schema on Q&A sections. Validate in Google's Rich Results Test.
Mistake 6 — Optimizing for All Platforms Equally
You try to satisfy Perplexity's recency bias, ChatGPT's definition preference, Google AI Overview's table preference, and Claude's procedural preference in the same article. The result is a structurally confused piece that satisfies none of them. Fix: Choose a primary platform target and a secondary. Structure for the primary. Include one or two elements for the secondary.
How to Implement AI Citation Engineering in Your Content Workflow
AI Citation Engineering is not a one-time optimization. It's a production discipline that integrates into every stage of content creation.
Stage 1 — Signal 0 Confirmation (Before Any Content Is Created)
Run the GEO Technical Onboarding Checklist for your domain. Confirm: Organization schema live with @id URI, Wikidata QID, logo, sameAs links. Person schema live for every author with persistent @id URIs. Canonical naming rules documented in the entity_spine section of your content brief template. Signal 0 is the gate. No content enters production until this is complete.
Stage 2 — Brief Development
For every article, complete a structured brief that includes: signal_0_confirmed: true (hard requirement), entity_spine with canonical names and forbidden variations, information_gain_directive stating what this article adds that does not exist elsewhere, platform_citation_target (Primary / Secondary), and cluster_position (standalone, pillar, or cluster feeding a named pillar). The brief is not a wish list. It's an engineering specification.
Stage 3 — Drafting Against the Citation Architecture
Write to the eight signals: Signal 03 (named entities in first paragraph), Signal 04 (temporal markers), Signal 05 (author credentials, inline citations), Signal 06 (Opening Answer Block, answer-first H2 structure), Signal 07 (intent-mapped headings), Signal 08 (Information Gain identified and stated). Do not draft, then optimize. Optimize as you draft.
Stage 4 — Technical Implementation
Before publishing: generate Article schema with all required fields, FAQ schema if Q&A sections present, HowTo schema if procedural steps present, DefinedTerm schema for any concepts defined. Validate all schema blocks in Google's Rich Results Test. Fix errors before publishing.
Stage 5 — Distribution and Seeding
Within 48 hours of publishing, seed the article in 2–3 external communities: relevant subreddit (post as resource, not promotion), Quora answer linking to the article as supporting evidence, LinkedIn post from the author (organic share, not link drop). Distribution velocity compounds retrieval probability.
Stage 6 — Citation Monitoring (30-Day Validation)
30 days post-publish, run citation monitoring queries in Perplexity, ChatGPT, and Google AI Overview. Log: citation status (cited / not cited), citation position (1st source, 2nd source, etc.), attribution format (full / partial / none), competing sources cited. If not cited, diagnose: was content retrieved but not cited? (Extraction issue — Signal 06 or 07.) Was content not retrieved at all? (Retrieval issue — Signal 03, 04, or 05.) Iterate based on data.
Frequently Asked Questions
How long does it take to see AI citation results?
RAG citations can appear within 48–72 hours of publishing if the article is indexed and optimized for Signals 03–07. Training data citations take 6–12 months of sustained topical authority across a content cluster. Most clients see their first Perplexity or ChatGPT citation within 30 days of implementing the Citation Architecture, assuming Signal 0 is complete and the article targets a query with medium competition.
Can I get cited if my domain authority is low?
Yes. AI retrieval systems prioritize entity disambiguation, freshness, and extraction clarity over domain authority. A new site with strong Signal 0 infrastructure, clear entity signals, and answer-first structure will out-cite an established site with generic content and no schema. Backlinks still matter for indexing speed, but they don't control RAG retrieval probability the way they controlled PageRank.
Do I need to optimize every old article, or can I start with new content?
Start with new content. Implement Signal 0 first (Organization and Person schema), then apply the Citation Architecture to every new article you publish. Retroactively optimize high-traffic articles (top 10–20 by monthly visits) by adding schema, freshness markers, and Opening Answer Blocks. Do not attempt to optimize your entire content library at once — it's not scalable and the ROI is lower than focusing on new production and top performers.
What's the difference between AI Citation Engineering and traditional SEO?
SEO optimizes for ranking position in a list of links. AI Citation Engineering optimizes for retrieval probability and extraction clarity in systems that synthesize answers without requiring clicks. SEO assumes the click is the goal. AI Citation Engineering assumes the citation is the goal. SEO measures traffic. AI Citation Engineering measures branded search lift, citation count, and attribution presence.
Which AI platform should I optimize for first?
Depends on your audience. Researchers, strategists, high-intent B2B buyers → Perplexity first (recency, named entities, inline citations). General consumers or students → ChatGPT (definitions, FAQ schema, structured extractability). Google-primary audiences → Google AI Overview (tables, lists, Knowledge Graph entities). Most B2B brands: Perplexity primary, ChatGPT secondary.
Can I use AI-generated content and still get cited?
Yes, if the content satisfies Signals 03–08. The issue with most AI-generated content is not that it's AI-written — it's that it's generic, entity-sparse, and lacks Information Gain (Signal 08). AI-generated content optimized for the Citation Architecture (entity-dense, answer-first structure, temporal markers, novel synthesis) performs identically to human-written content in RAG retrieval. The quality gate is Signal 08: does this content contribute something new to the discourse?
How often should I update content to maintain citation velocity?
Perplexity citations decay fastest — update every 60–90 days with fresh examples, new statistics, or temporal markers. ChatGPT citations persist longer — update every 6 months unless the topic is fast-moving (software, regulation, market data). Google AI Overview citations last longest for Knowledge Graph entities — update annually unless there's a significant change in the topic.
Do I need a Wikidata entry to get cited?
Not required for RAG citations, but strongly recommended for training data citations and Google AI Overview. Wikidata QID in your Organization schema links you to the Knowledge Graph, which increases retrieval probability for entity-focused queries. Creating a Wikidata entry is free and takes 15–30 minutes — include it in your Signal 0 setup.
Next Steps: Build Your Citation Engine
AI Citation Engineering is not a tactic. It's a production discipline.
The brands that dominate the next decade of search will be the ones that engineer for citation deliberately — Signal 0 infrastructure, entity-dense content, answer-first structure, and Information Gain across every article.
- Confirm Signal 0 is complete. Organization schema, Person schema for authors, canonical naming rules enforced. No exceptions.
- Audit your top 10 articles. Do they include Opening Answer Blocks? Temporal markers? Schema markup? Named entities in the first paragraph? Fix the gaps.
- Implement the brief template. Every new article starts with entity_spine, information_gain_directive, and platform_citation_target. No articles enter production without a completed brief.
- Run citation monitoring for your core topics. 10–15 queries in Perplexity, ChatGPT, and Google AI Overview. Note whether you're cited. Log competing sources. Repeat monthly.
- Build one content cluster optimized for RAG. Choose a pillar topic. Write 5–7 cluster articles feeding it. Apply Signals 03–07 to every article. Interlink with semantic anchors. Monitor citation lift across the cluster.
The citation is the new click.
Engineer for it.
Find out which signals your domain is missing.
Run Free Check →