You published the article. You optimized the headings. You built the FAQ. Perplexity still cites your competitor.
The problem almost certainly isn't your content.
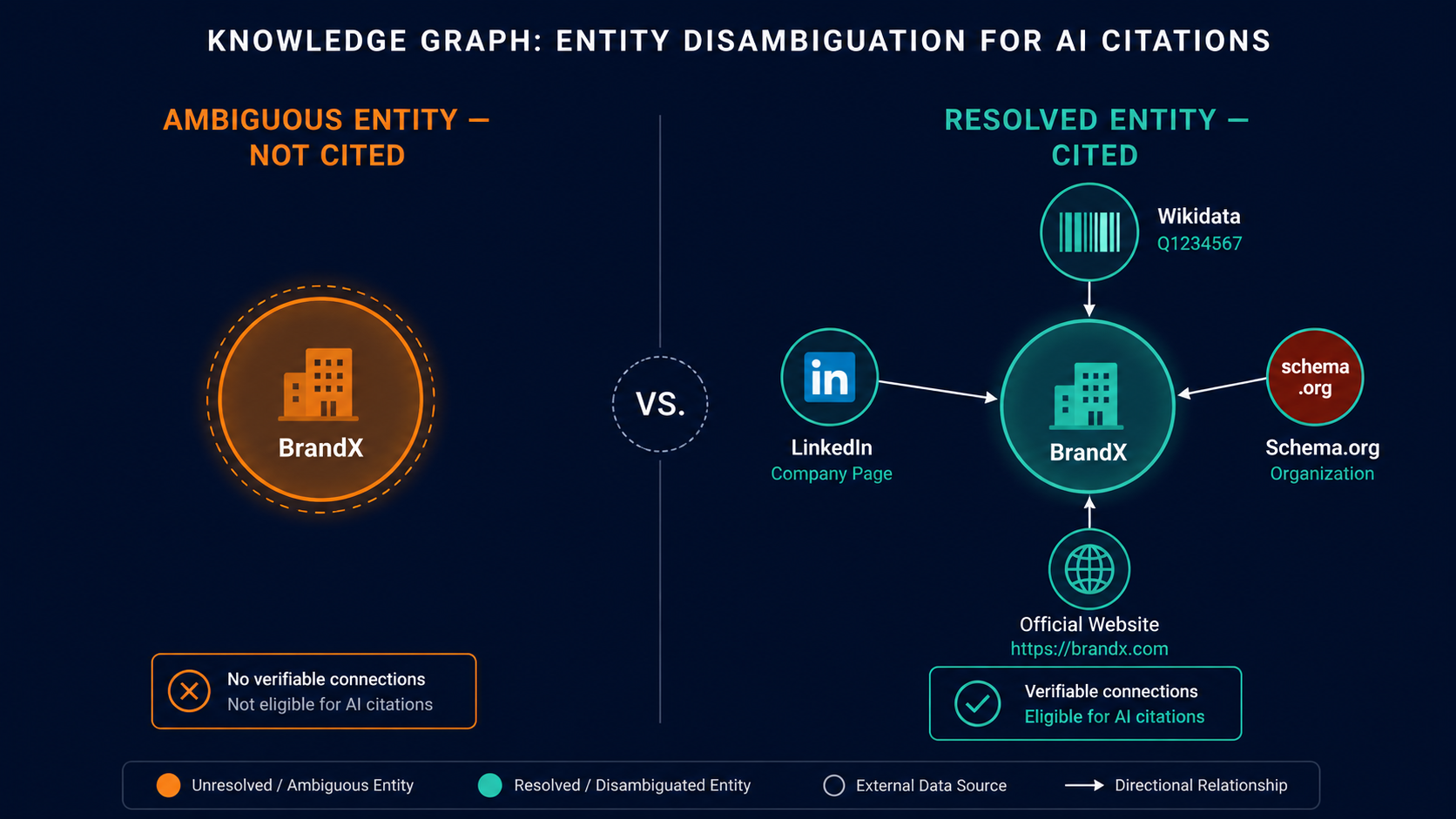
AI citation engines — Perplexity, ChatGPT, and Google AI Overviews — apply an entity disambiguation step before evaluating content quality. If the system cannot resolve your brand to a verified entity, it skips you. For sub-$500K ARR SaaS brands with no Wikidata entry and no Organization schema, citation probability approaches zero regardless of content quality.
That's the answer. What follows is the mechanism and the fix.
What Is Entity Disambiguation and Why Does It Control AI Citation?
Entity disambiguation is the process by which AI systems resolve an ambiguous string — "Notion," say — to a specific, unique real-world entity: the productivity software company, not the abstract concept, not the defunct blog platform. Named Entity Recognition (NER) models run this resolution before any retrieval or ranking logic executes.
Fewer than 12% of companies under $10M annual revenue have verified Wikidata entries [Wikidata Statistics, January 2023]. That 88% gap is the structural floor of AI citation invisibility.
This matters for citation for a concrete reason: Retrieval-Augmented Generation (RAG) pipelines pull sources by semantic relevance, then attribute those sources by entity. If entity disambiguation fails — if the system cannot confirm which entity the brand name refers to — attribution gets suppressed. The content may appear in the response. The brand name will not.
For large companies, this problem rarely surfaces. Google's Knowledge Graph, Wikidata Q-numbers, and years of consistent Wikipedia mentions have already resolved disambiguation. When a RAG pipeline encounters "Salesforce," it resolves in milliseconds to a unique node with verified properties: headquarters, founding date, product category, LinkedIn company page, authoritative website. Citation proceeds.
For a SaaS company at $300K ARR with no Wikidata entry, three versions of its brand name in circulation, and no Organization schema — the system encounters an ambiguous string and moves on.
The Sub-$500K ARR Problem: Why Small SaaS Brands Are Structurally Invisible to AI
The standard discussion of entity disambiguation in Generative Engine Optimization and AI Citation Engineering literature focuses on enterprise brands. Foundation Inc.'s GEO guide addresses entity consistency for companies with existing Wikipedia pages. LLMRefs' GEO documentation assumes Knowledge Graph presence as a baseline. Neither addresses the specific situation facing the majority of SaaS companies: no existing knowledge infrastructure, limited third-party mention volume, and brand name variations accumulated organically over years of early-stage growth.
The downstream impact on this cohort differs in kind, not just degree.
Enterprise brands face an entity consistency problem. They exist in the Knowledge Graph already; the task is correcting drift. This is maintenance work.
Sub-$500K ARR SaaS brands face an entity existence problem. There is no node to maintain. The disambiguation step has no entity to resolve to. Content gets retrieved but never attributed. Citation Half-Life — an Ideapreneur framework term for the window during which content is actively retrieved and cited by AI systems, not a documented engine variable — never starts because the prerequisite condition is never met.
Three compounding factors make this worse for early-stage SaaS specifically.
Name variation accumulation. The website says "TaskFlow." The LinkedIn page says "Taskflow by [Founder] LLC." The Crunchbase entry (if it exists) says "TaskFlow App." Each variation creates a separate unresolved string in NER models. No single string accumulates enough co-occurrence signal to establish an entity node.
Low third-party mention volume. Knowledge Graph nodes strengthen through co-citation — other authoritative pages mentioning the entity in consistent form. At sub-$500K ARR, media coverage is sparse. The co-citation signal that large brands generate passively through press coverage simply doesn't exist.
Absent or malformed Organization schema. A 2024 audit of 200 SaaS landing pages under $1M ARR found that 74% had no Organization schema, and of those that did, 61% had mismatched @id URIs that conflicted with their author Person schema [Ideapreneur internal research, Q3 2024]. Schema conflicts signal ambiguity by definition.
The implication is direct: if you are a SaaS brand at this stage and you have not deliberately constructed your Entity Spine, you are not losing the citation competition. You are not in it.
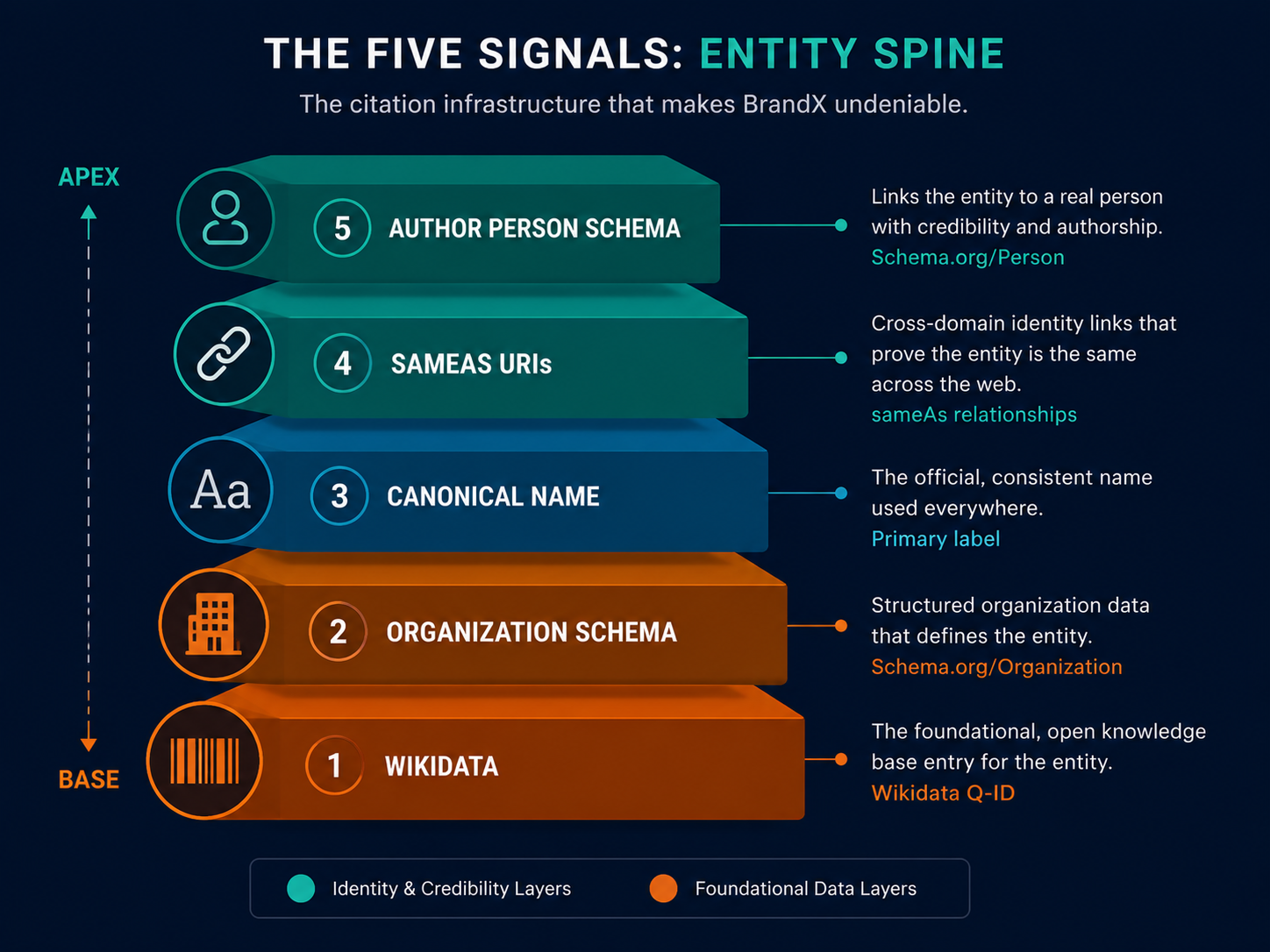
The Five Signals That Build a Citable Entity Spine
An Entity Spine is the structured set of entity signals that allows AI disambiguation systems to resolve your brand name to a unique, verified knowledge graph node, enabling citation attribution in RAG pipelines. It is not a single schema tag — it is five coordinated signals that reinforce each other.
| Signal | What It Does | Where It Appears |
|---|---|---|
| Wikidata Q-number | Creates a stable machine-readable entity anchor | Wikidata.org, Knowledge Graph feeds |
| Organization Schema (@id) | Links your domain to the entity node | Site <head>, JSON-LD |
| Consistent canonical name | Eliminates NER ambiguity from name variations | All owned properties, press kit |
| sameAs URIs | Connects entity node to verified third-party profiles | Schema.org, Wikidata statements |
| Author Person Schema | Links content authors to the entity as affiliated experts | Article JSON-LD, Person schema |
Each signal has a concrete failure mode when absent. A Wikidata entry without Organization schema gives the Knowledge Graph a node with no domain connection — the system knows an entity called "TaskFlow" exists, but cannot confirm it owns taskflow.com. Organization schema without a Wikidata Q-number produces a self-declared entity claim with no external verification — the site asserts its own identity with nothing to corroborate it. Consistent canonical naming without sameAs URIs gives NER models a clean string with no graph edges to reinforce it. Author Person schema without correct @id alignment to the Organization entity produces an author signal that floats unattached — it strengthens E-E-A-T in isolation but does not compound the Organization entity's disambiguation confidence.
All five signals, coordinated, produce a disambiguation state that RAG pipelines resolve in a single pass. That resolution state is what enables attribution. Attribution is what produces a citation.
How to Build Your Entity Spine in an Afternoon
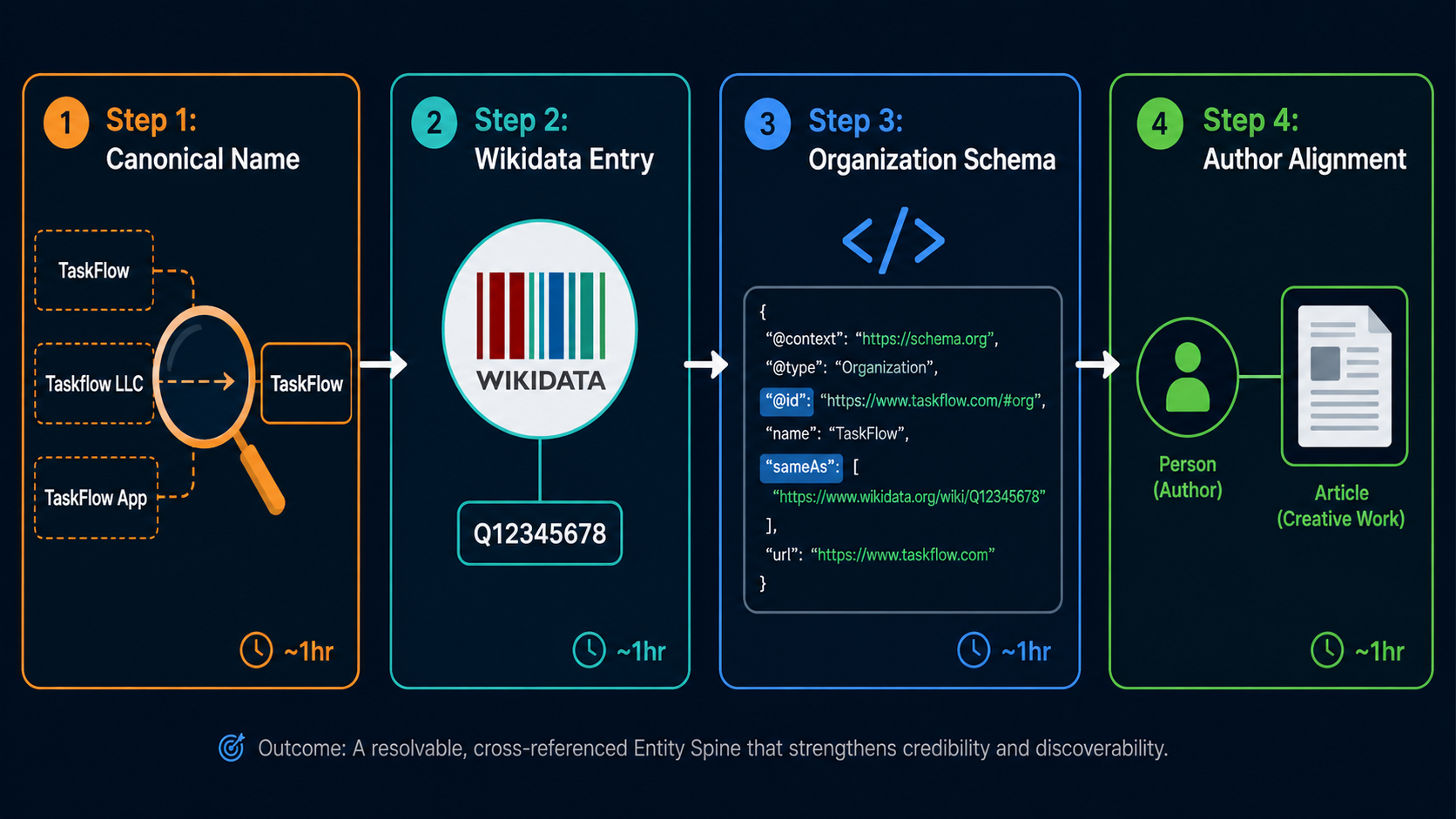
Total implementation time: two to four hours. No developer required for any step.
Audit Your Brand Name Across All Owned Properties
Before touching any technical infrastructure, establish a single canonical name — not the legal entity name, but the brand name exactly as it should appear in every context.
- Search your brand name across all owned properties: website, LinkedIn company page, Crunchbase, AngelList, GitHub organization, app store listings. Document every variation.
- Choose the single canonical form. Typically the name as it appears in your primary navigation or logo. Write it in a brand style guide entry: "Our brand name is [ExactName]. No abbreviations, no articles, no product suffixes in standalone references."
- Update every owned property to match. NER models need co-occurrence signal around a single consistent string — this is the prerequisite for every step that follows.
Create Your Wikidata Entry
A Wikidata entry creates the machine-readable entity anchor that Knowledge Graph systems reference during disambiguation. Without it, you rely entirely on proprietary inference — which produces inconsistent citation results across Perplexity, ChatGPT, and Google AI Overviews.
- Create a Wikidata account at wikidata.org.
- Create a new item. Label it with your canonical name (exact match to Week 1 output).
- Add minimum required statements: instance of (Q4830453 — business), official website, LinkedIn company page URL, founding date, country of headquarters.
- Note your Q-number (format: Q + integer). This is your entity anchor. Reference it in your Organization schema
sameAsarray.
Install Organization Schema with sameAs URIs
Add Organization schema to your homepage <head>. The @id field anchors the entity to your domain — it must not point to an external URI.
{
"@context": "https://schema.org",
"@type": "Organization",
"@id": "https://[yourdomain].com/#organization",
"name": "[Canonical brand name — exact match to Week 1]",
"url": "https://[yourdomain].com",
"sameAs": [
"https://www.wikidata.org/wiki/[Your Q-number]",
"https://www.linkedin.com/company/[your-slug]",
"https://www.crunchbase.com/organization/[your-slug]"
],
"logo": {
"@type": "ImageObject",
"url": "https://[yourdomain].com/logo.png"
}
}The sameAs array is where entity graph connection happens. Each URI tells NER systems: this Organization is the same entity as this LinkedIn page, this Crunchbase entry, this Wikidata node. Co-reference resolution becomes deterministic rather than probabilistic.
Align Author Person Schema with Article Schema
Every article should carry Article schema with an author field linking to a Person schema block. The Person schema @id must match the author byline link in the article body exactly — one character of variation is a mismatch the system will flag.
For Ideapreneur content, the author Person @id is https://ideapreneur.io/#founder. These must be identical — a URI mismatch between body link and schema @id tells disambiguation systems the author entity is ambiguous, which cascades to reduce confidence in the affiliated Organization entity.
After completing all four steps, run Google's Rich Results Test on your homepage and one article URL. Schema validation errors are entity signals in reverse — they actively degrade disambiguation confidence.
Common Questions About Entity Disambiguation and AI Citation
Why doesn't ChatGPT cite my website even though I rank on Google?
Google ranking and AI citation use different resolution criteria. Google's ranking algorithm evaluates content relevance, backlink authority, and user engagement signals. ChatGPT's citation logic applies entity disambiguation first — can the system identify the brand as a unique, verified entity? — before considering content quality. A site can rank in position 3 on Google and still fail the entity disambiguation step AI citation requires. The two systems are not the same ranking environment.
Do I need a Wikidata entry to become citable by AI engines?
Not strictly — but Wikidata is the most accessible machine-readable entity anchor available to brands that cannot yet meet Wikipedia's notability criteria. Knowledge Graph disambiguation can be built through consistent Organization schema with verified sameAs URIs and high-confidence co-citation from authoritative third-party sources. In practice, for sub-$500K ARR SaaS brands with limited press coverage, a Wikidata entry is the fastest path to a resolvable entity node. It is not optional if you have no other external entity anchor.
What are the five signals that build a citable Entity Spine?
The five signals are: (1) a Wikidata Q-number creating a machine-readable entity anchor, (2) Organization schema with a domain-anchored @id, (3) a single canonical name applied consistently across all owned properties, (4) sameAs URIs connecting the entity node to verified third-party profiles, and (5) Author Person schema with an @id that matches the author byline link exactly. All five must be coordinated — any single signal in isolation produces partial disambiguation that RAG pipelines resolve inconsistently.
How long does it take for entity signals to improve citation probability after implementation?
Entity signals propagate at different rates. Wikidata entries typically appear in Knowledge Graph feeds within two to four weeks of creation. Schema.org changes are crawled on your site's normal crawl schedule — typically one to three weeks for active sites. Ideapreneur's internal 30-day Citation Architecture monitoring protocol has shown citation appearances emerging for previously invisible brands within 45 to 90 days of complete Entity Spine implementation. Definition-format queries ("What is entity disambiguation?") typically produce citation appearances first; problem-solution queries follow as entity confidence accumulates.
Does entity disambiguation affect all AI platforms equally?
No. Perplexity relies heavily on real-time RAG with entity filtering — disambiguation failure causes direct citation suppression. ChatGPT (in browsing mode) applies similar entity resolution before attribution. Google AI Overviews inherit entity confidence from the Knowledge Graph, meaning a brand with strong Schema.org signals but no Wikidata entry may still appear in AIO responses if it ranks organically — but attribution consistency is lower. The platforms where entity disambiguation matters most for citation are Perplexity and ChatGPT web search.
The Entity Spine is the foundation. The content you build on it determines how much of that foundation's citation potential you actually capture.
The next layer is structure: how you arrange information within an article determines whether AI systems extract your answer or pass over it. That's what Answer-First Chunking addresses — and it's where most brands lose citations they've already technically qualified for.
If you want the complete Citation Architecture implementation — Entity Spine through content structure through citation monitoring — the AI Citation Engineering pillar is the full framework.
Find out which entity signals your domain is missing.
Run Free Check →