Brands disappear from AI-generated answers for five specific reasons: AI crawlers can’t access the site, AI systems can’t identify the brand as a named entity, content isn’t structured for extraction, schema markup is absent or broken, or content is new and hasn’t been indexed by AI systems yet. Each failure mode has distinct diagnostic signals and a distinct fix. Identifying the correct one before attempting remediation saves significant time.
Something has changed about how people find information, and you’ve probably noticed it in your traffic data before you noticed it anywhere else. Fewer clicks. Stable rankings. Declining organic visits from queries where you still technically appear on page one.
What happened is that for a growing category of searches — definitions, comparisons, how-to questions, diagnostic queries — a significant portion of users now get their answer from ChatGPT, Perplexity, or a Google AI Overview without visiting any website at all. And when that answer gets constructed, your brand either gets named or it doesn’t.
If it’s not getting named, something specific is broken. Not “your SEO strategy needs work.” Something specific, identifiable, and fixable — if you know what to look for.
There are five things that can cause AI invisibility. This article names all five, gives you the questions to diagnose which one is yours, and routes you to the fix. The pillar’s job is identification. The spokes handle remediation.
How AI Search Systems Actually Decide What to Cite
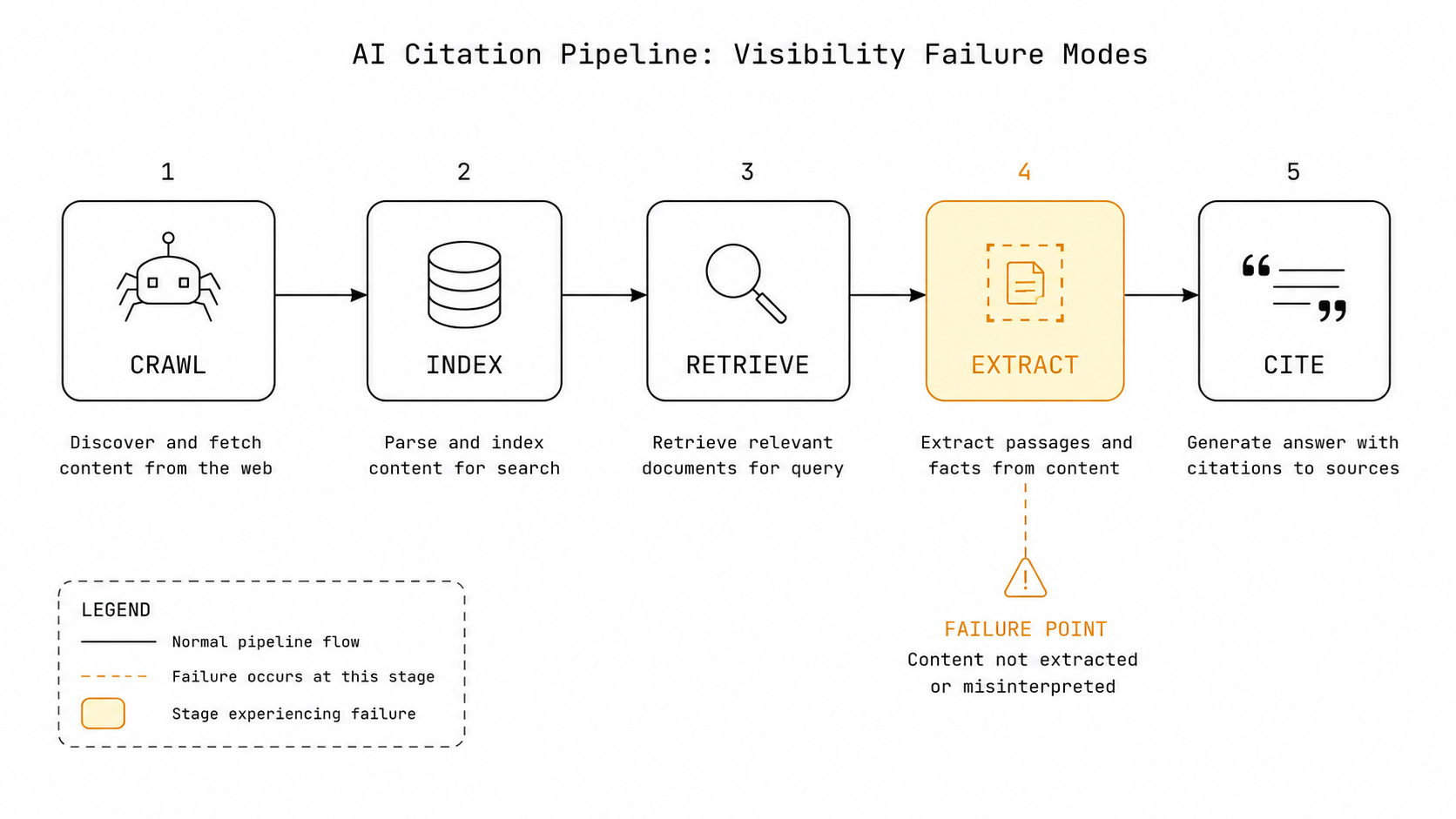
Before diagnosing what’s broken, it’s worth understanding the pipeline that has to work correctly for your brand to appear in an AI-generated answer at all. Most “optimize for AI” advice skips this step, which is how you end up with practitioners adding FAQ schema to a site that OAI-SearchBot can’t crawl. Schema on a blocked site is decoration.
The citation pipeline has five stages. Every stage is a potential failure point.
Stage 1 — Crawl. An AI platform’s bot visits your site and reads the content. ChatGPT uses OAI-SearchBot. Perplexity uses PerplexityBot. Google AI Overviews use Google-Extended, among other crawlers. If your robots.txt, server firewall, or WAF blocks these bots, the pipeline stops at stage one. The rest is irrelevant.
Stage 2 — Index. The crawled content enters the platform’s index or retrieval layer. This is not the same as Google’s index. AI platforms maintain their own retrieval systems, and indexing timelines vary — sometimes significantly.
Stage 3 — Retrieve. When a user asks a question, the AI system queries its retrieval layer for relevant content. At this stage, entity density, semantic relevance, and content freshness all affect whether your page surfaces.
Stage 4 — Extract. The AI system pulls specific passages from the retrieved content to construct its answer. This is where structure matters. Answer-first paragraphs, FAQ blocks, and well-formed headings are extraction targets. Walls of prose are not.
Stage 5 — Cite. The AI system attributes the extracted passage to a source. This is where brand identity becomes critical. If the system can’t confidently identify who owns this content — no Organization schema, no consistent brand name, no off-site corroboration — attribution gets suppressed or attributed generically.
Miss any stage, and your brand doesn’t appear. The diagnostic question isn’t “am I optimized for AI?” It’s “which stage is failing?”
The Five Failure Modes — Diagnostic Overview
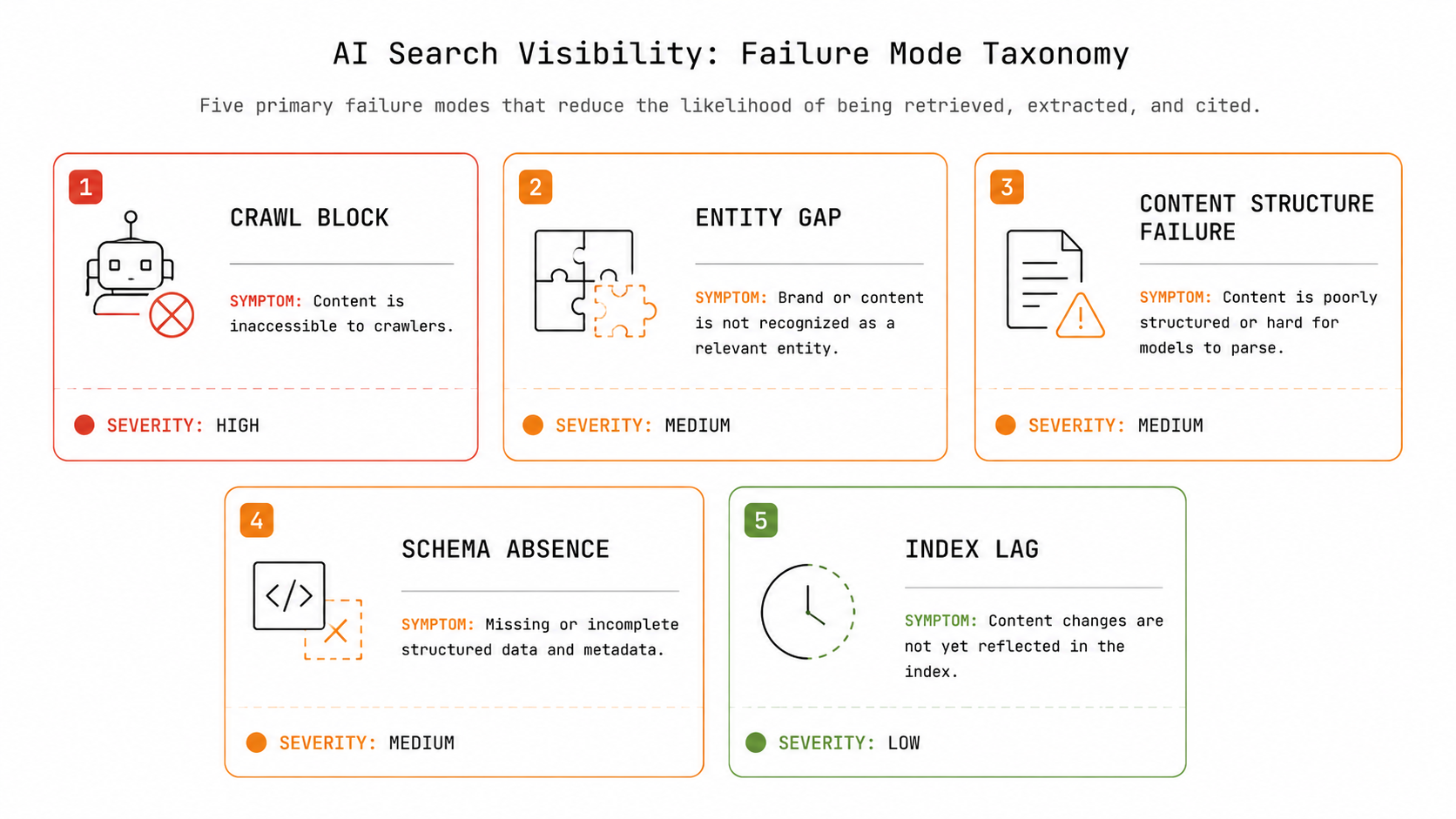
Here is the full taxonomy. Each row maps a failure mode to its primary symptom and the spoke that covers remediation. This table is the fastest way to orient yourself before reading the detailed diagnostic sections below.
| Failure Mode | What’s Breaking | Primary Symptom |
|---|---|---|
| Crawl Block | AI bots can’t read your site | Competitors cited; you’re not — despite comparable content |
| Entity Gap | AI systems can’t identify your brand | Brand name absent from AI answers even when content is retrieved |
| Content Structure Failure | Content isn’t extraction-ready | AI answers describe your topic but don’t name you as a source |
| Schema Absence | Structured data missing or broken | Inconsistent citation; AI can’t categorize page type or authorship |
| Index Lag | Content not yet in AI retrieval layer | New content; all other factors confirmed healthy |
Work through the sections below in order. Each failure mode is independent — you may have more than one — but Crawl Block invalidates all downstream diagnostics, so start there.
Failure Mode 1: Crawl Block
What it is
AI crawlers are software bots that visit websites to read and index content. OAI-SearchBot (ChatGPT), PerplexityBot (Perplexity), and Google-Extended (Google AI Overviews) all need to access your pages before any downstream optimization matters.
A crawl block means one or more of these bots is being turned away at the door. Your content could be brilliantly structured, semantically dense, and schema-perfect — if the bot never reads it, none of that matters. This is the failure mode people fix last because they assume access was never a problem. It’s frequently the only problem.
There are four common sources of crawl block for AI bots specifically. Standard SEO audits don’t catch all of them because traditional SEO only tracks Googlebot — not the AI-specific user agents.
robots.txt rules. A Disallow: / rule, or a rule disallowing the specific bot user agents listed above, will block crawling site-wide. Many sites added aggressive bot-blocking rules during the 2023–2024 period when AI scraping concerns peaked. Some of those rules are still live.
llms.txt. A relatively new convention that explicitly signals to AI systems which content is available for training and retrieval. An improperly configured llms.txt — or one that disallows all AI access — can suppress crawling from platforms that honor it. Perplexity and some others check for it. What llms.txt is and whether your site needs it covers this in full.
WAF and firewall rules. Web Application Firewalls set up to block bot traffic often catch AI crawlers in their net. If your WAF is rate-limiting or blocking non-Googlebot user agents, OAI-SearchBot and PerplexityBot may be hitting a 403 before they index a single page.
JavaScript-heavy rendering. If your site requires JavaScript execution to surface content and your server doesn’t pre-render, some AI crawlers — which have varying JS execution capabilities — may crawl a blank page.
Diagnostic questions
Before moving to Failure Mode 2, answer these:
- Does your robots.txt explicitly allow OAI-SearchBot, PerplexityBot, and Google-Extended? Or does it use a blanket
Disallowthat would catch them? Checkyoursite.com/robots.txtright now. If you seeUser-agent: *followed byDisallow: /, that’s a full block on every bot including AI crawlers. - Has your WAF or hosting provider added bot protection rules in the past 18 months? If you’re on Cloudflare, check your bot management settings. “Block all bots” is not an uncommon default for security-conscious setups — and it’s an AI citation killer.
- Are competitors being cited for the same queries where you’re absent — despite your content being comparable in quality and length? If yes, and if the gap appeared after a site migration, hosting change, or security update, crawl block is a high-probability diagnosis.
If any answer raises a flag, resolve the crawl block before proceeding to the other failure modes.
Failure Mode 2: Entity Gap
What it is
This one is subtler, and it trips up good SEOs who’ve never had to think about brand identity as a technical problem before.
AI systems don’t just retrieve content — they attribute it. When Perplexity or ChatGPT surfaces your article in response to a user query, it names a source. That source identification happens via entity resolution: the AI system needs to determine who owns this content, whether that entity is credible, and whether it can name that entity with confidence.
If your brand doesn’t exist as a recognizable entity in the AI’s knowledge layer — no Organization schema, no consistent canonical name across pages, no corroborating off-site mentions connecting your brand name to your domain — attribution gets suppressed. The content might be retrieved. The passage might even be extracted. But the citation gets generic, gets attributed to a competitor whose entity is clearer, or gets dropped.
Entity gaps are caused by a specific cluster of problems. Missing or malformed Organization schema means the AI can’t programmatically identify your organization. Inconsistent brand naming — “Ideapreneur” on one page, “ideapreneur.io” on another, “the Ideapreneur team” in a byline — creates ambiguity the AI resolves by not naming you. Absent off-site signals (Wikipedia entry, Wikidata record, authoritative directory listings, press mentions) mean the AI has no corroboration that your brand is a real, persistent entity rather than a one-off content source.
In the Citation Architecture framework, this is what the Entity Spine addresses — establishing the brand as a citable named entity before content production begins, rather than after. The Entity Spine isn’t a content optimization. It’s an identity declaration.
Diagnostic questions
- Does your site have Organization schema deployed on every page, with a consistent
@idURI,namethat matches your canonical brand name exactly, andsameAslinks to verified social profiles? If you’re not sure, paste your homepage source into Google’s Rich Results Test. No Organization schema means no entity anchor. - Is your brand name used identically — same capitalization, same spacing, same format — across your homepage, About page, author bylines, and meta tags? Variations aren’t a style problem. They’re entity ambiguity signals.
- Does your brand appear in any off-site context that an AI training dataset would have encountered? Industry directories, press mentions, third-party review sites, Wikidata entries. If you’ve never existed anywhere except your own website, you’re invisible to the entity resolution layer.
If any answer is no, close the entity gap before optimizing content structure.
Failure Mode 3: Content Structure Failure
What it is
Here’s the frustrating scenario this failure mode describes: your site is crawlable, your brand is identifiable, and your content is genuinely good — but you’re still not showing up in AI answers. Or you’re showing up, but without attribution. Or competitors with objectively worse content are being cited instead.
Content structure failure is what happens when AI extraction can’t find a usable passage in your article. Not because the content is bad, but because it isn’t organized the way AI retrieval systems extract information.
AI systems — specifically the RAG (Retrieval-Augmented Generation) pipelines that power Perplexity, ChatGPT web search, and Google AI Overviews — extract answer-sized chunks. They’re looking for: a direct answer to a question, within the first 150 words of a section, stated in plain language, self-contained enough to be cited without surrounding context. What they’re not looking for: a 600-word flowing essay that eventually arrives at a point somewhere in the fourth paragraph.
The structure problem has three main expressions.
Buried answers. The H2 heading says “Understanding AI Search Citation” but the actual answer to what that means doesn’t appear until paragraph three of the section. AI extractors read the heading, pull the opening paragraph, and move on. If your answer is in paragraph three, it doesn’t get extracted.
Heading vagueness. “AI Search Overview” is not an extraction target. “Why AI Search Systems Skip Well-Written Content” is. Intent-mapped headings — phrased the way users ask questions — dramatically increase extraction probability because they signal to the AI retrieval system that this section directly addresses a query.
Missing FAQ structure. FAQ Q&A blocks are one of the highest-yielding structural elements for AI citation. A question phrased as an H3, followed by a 100–150 word standalone answer, is purpose-built for extraction. Perplexity excerpts FAQ blocks at a disproportionately high rate relative to their word count.
The RAG claim-evidence proximity rule compounds this. In AI retrieval, a claim without its supporting evidence within the same paragraph — or the paragraph immediately following — gets flagged as unsupported during extraction and is less likely to be cited. Your evidence can’t be three sections away from your claim.
Diagnostic questions
- Does the first paragraph of every major section begin with a direct answer to the question implied by its H2 or H3 heading? Read just the first sentence of each section. If it’s context-setting rather than answering, you have a buried-answer problem.
- Are your H2 and H3 headings phrased as specific questions or verb-led statements — the way a user would search? Or are they topic labels (“AI Search,” “Content Strategy,” “Schema”)? Topic labels are not extraction targets.
- Does the article include at least one FAQ section with questions phrased as users ask them, followed by complete standalone answers of 100–150 words each? If FAQ is absent or thin, extraction probability drops significantly for question-format queries.
If any answer is no, restructure the article for answer-first extraction before revisiting schema.
Failure Mode 4: Schema Absence
What it is
Schema markup is structured data — code embedded in your page that tells AI systems (and search engines) what type of content this is, who wrote it, what it defines, and how its parts relate to each other. Without schema, an AI system is reading your page the way someone reads a document with no title, no byline, no headers, and no table of contents: it can probably figure out the gist, but it’s working much harder than it should, and it’ll reach for a more parseable source when one is available.
Schema absence is distinct from entity gap (Failure Mode 2), though they’re related. Entity gap is about brand identity — the AI doesn’t know who you are. Schema absence is about content classification — the AI doesn’t know what the page is, who wrote it, or how to categorize its parts.
Four schema types are most critical for AI citation probability.
Article schema establishes the content type, author identity, publication date, and publisher. It’s the minimum viable schema for any content asset. Without it, AI systems can’t programmatically confirm authorship, recency, or brand affiliation.
FAQ schema marks up Q&A sections as structured question-answer pairs. Perplexity and Google AI Overviews both extract from FAQ schema at elevated rates — the structure tells the retrieval system exactly where the answer to a question lives.
DefinedTerm schema marks up concept definitions. If your article defines “AI Citation Engineering” or “Generative Engine Optimization,” a DefinedTerm block tells AI systems this page is an authoritative source for that definition. ChatGPT citations favor definitional content; DefinedTerm schema makes the definition findable.
HowTo schema marks up procedural content. If you’re explaining a process with numbered steps, HowTo schema tells the AI system this is actionable procedural content — a category Claude and ChatGPT cite at elevated rates.
A common variant of schema failure worth naming: schema exists but is broken. Missing required fields (datePublished in Article schema, acceptedAnswer text in FAQ schema), mismatched @id URIs between Article schema and Organization schema, or template variables that were never populated (“author”: “[AUTHOR_NAME]”) all produce schema that validates as present but doesn’t function. Google’s Rich Results Test will show these as warnings or errors.
Diagnostic questions
- Does every article page include Article schema with populated
headline,author(with@idandname),datePublished,dateModified, andpublisher? Paste the page URL into Google’s Rich Results Test. If Article schema isn’t detected, it’s absent or broken. - If the article contains Q&A sections, does it have FAQPage schema marking up each question-answer pair? If you have a FAQ section in your article body but no FAQ schema in the page source, you’re leaving one of the highest-yield extraction signals unused.
- Are any schema template variables still unpopulated? Search your page source for bracket patterns like
[AUTHOR_PROFILE_URL],[PUBLISH_DATE], or[ORGANIZATION_LOGO_URL]. These are schema blocks that were generated but never completed — they register as malformed data.
If any answer is no or uncertain, implement schema before assuming content or entity factors are responsible.
Failure Mode 5: Index Lag
What it is
This one is the least satisfying diagnosis because the fix is patience — but it’s also surprisingly common, and knowing it’s the issue prevents practitioners from making things worse by over-optimizing a site that just needs time.
Index lag describes the gap between when AI bots crawl your content and when that content becomes available in the AI system’s retrieval layer for active citation. This gap exists for all AI platforms, but it behaves differently from Google’s indexing timeline, which has conditioned most SEOs to expect relatively fast turnaround.
Google’s indexing pipeline for a well-established site can process new content in hours to days. AI citation indexing — the process by which content becomes citable in Perplexity’s real-time RAG pipeline or retrievable in ChatGPT’s web search — operates on a different cadence. Based on Ideapreneur’s first-party observations across Citation Architecture implementations, newly published content on sites without established AI citation history can take 30–90 days to appear consistently in AI-generated answers, even when all other failure modes are confirmed absent.
The mechanisms behind this lag are partially documented and partially opaque. Perplexity’s real-time search component retrieves content dynamically, so fresh content can theoretically appear immediately — but Perplexity also weights citation probability toward sources it has retrieved and validated repeatedly. A new piece of content from a new domain starts with zero citation history. ChatGPT’s web search (Bing-powered for the web retrieval layer) introduces Bing’s crawl and index schedule into the timeline. Google AI Overviews use Google’s index, but AI Overview inclusion isn’t simply a function of being indexed — content needs to clear additional quality signals before Google’s generation layer will excerpt it.
The practical implication: index lag doesn’t mean nothing is working. It means the pipeline is healthy but the retrieval history isn’t established yet.
The mistake practitioners make is diagnosing index lag as content structure failure (Failure Mode 3) or schema absence (Failure Mode 4) and spending weeks re-engineering content that was fine to begin with. The correct diagnostic sequence runs Failure Modes 1–4 first. If all four clear, index lag is the default remaining explanation.
Diagnostic questions
- Is the content in question less than 90 days old on a domain with no prior AI citation history? If yes, and if Failure Modes 1–4 are all confirmed clear, index lag is the most probable diagnosis.
- Does the domain have any confirmed AI citation history — has any content from this site been cited in Perplexity, ChatGPT, or Google AI Overviews at any point? A domain with zero citation history has a longer runway to first citation than an established domain adding new content.
- Are you seeing any early signals of retrieval — branded search volume increasing, traffic arriving from queries that match AI answer formats — even without confirmed citations? Early retrieval signals can appear before consistent citation does. They suggest the pipeline is working but the citation threshold hasn’t been cleared yet.
If index lag is your diagnosis, the primary intervention is patience combined with content velocity — publish additional content at regular intervals while the retrieval history builds.
Running the Full Diagnostic: Which Failure Mode Is Yours?
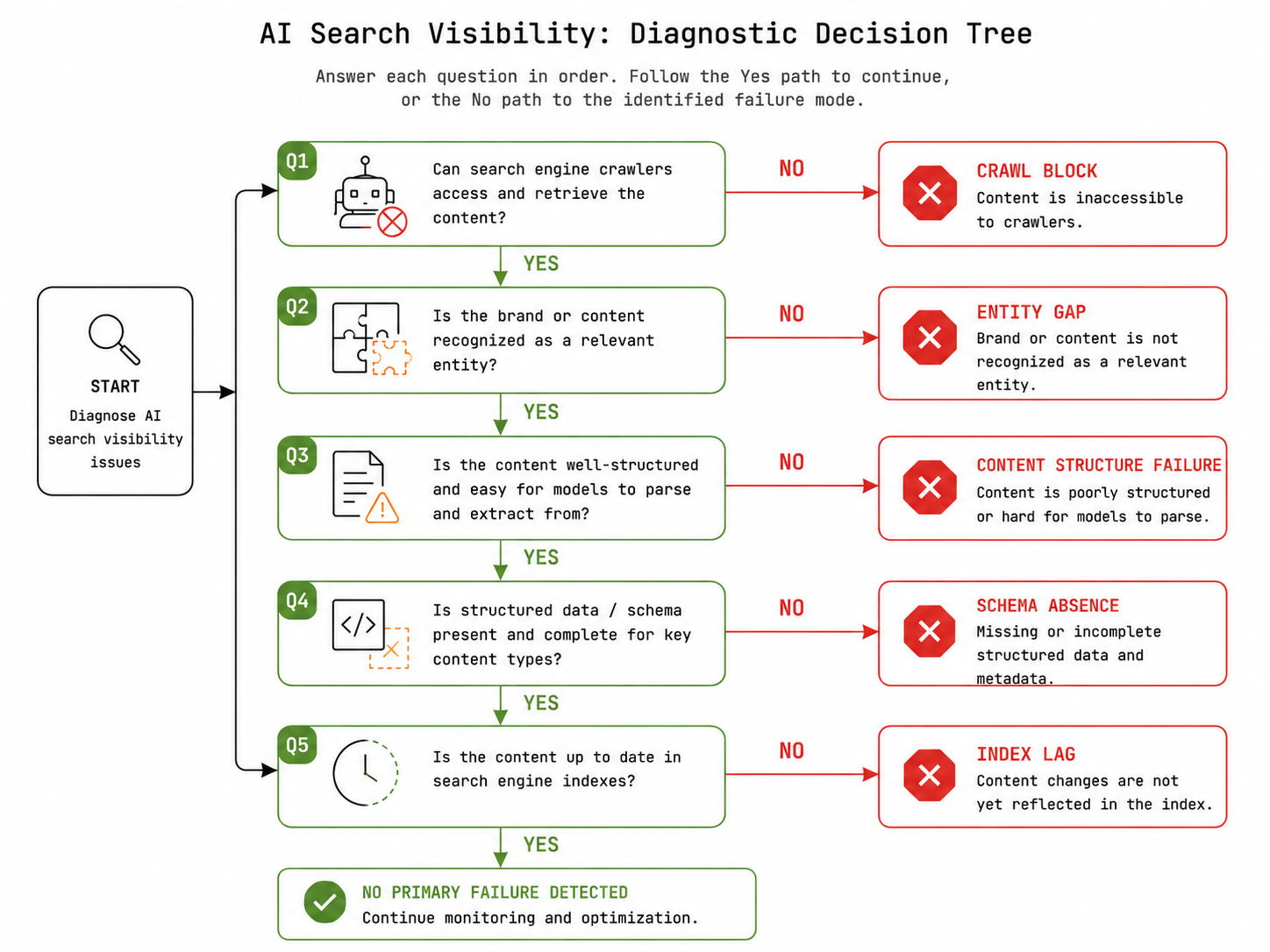
Work through these five questions in sequence. They’re ordered by pipeline stage — and since an earlier failure invalidates later diagnostics, sequence matters.
Question 1: Can AI crawlers access your site?
Go to yoursite.com/robots.txt. Look for User-agent: OAI-SearchBot, User-agent: PerplexityBot, and User-agent: Google-Extended. If these agents aren’t explicitly allowed — or if a blanket User-agent: * rule disallows crawling — stop here. Your failure mode is Crawl Block.
If AI crawlers have access, continue.
Question 2: Is your brand a recognized named entity?
Open your homepage source. Look for Organization schema with a populated @id URI, name matching your canonical brand name exactly, and sameAs links to verified social profiles. Then search your brand name in Perplexity or ChatGPT — not for your articles, but for your brand. Does the AI know your brand exists? If the answer is a blank, a hallucinated description, or a description of a different company, you have an entity problem. Your failure mode is Entity Gap.
If your brand is identifiable, continue.
Question 3: Is your content structured for extraction?
Pick your best article. Read only the first sentence of each H2 section. Does each one deliver a direct answer, or does it set context? Then look at your headings — are they phrased as questions or specific statements, or are they topic labels? Then check whether a FAQ section exists with standalone answers. If extraction-readiness fails any of these checks, your failure mode is Content Structure Failure.
If your content is structured correctly, continue.
Question 4: Is your schema present and complete?
Paste your article URL into Google’s Rich Results Test. Confirm Article schema is detected with no critical errors. Confirm FAQ schema is present if the article has Q&A sections. Search the page source for any unpopulated template variables in bracket format. If schema is absent, broken, or incomplete, your failure mode is Schema Absence.
If schema is present and complete, continue.
Question 5: How old is the content, and does the domain have AI citation history?
If the content is under 90 days old and the domain has no prior AI citation history, your failure mode is Index Lag. The pipeline is functional. The retrieval history isn’t established yet.
Most brands will identify their failure mode by Question 2 or Question 3. The diagnostic rarely makes it to Question 5 intact — which is useful information in itself.
What to Do Once You’ve Identified the Problem
The pillar’s job is diagnosis. Each failure mode has a dedicated remediation path covered in the spoke articles of this cluster.
Crawl Block: Audit robots.txt, test AI bot user agents explicitly by name, and configure llms.txt to signal permitted access to AI crawlers.
Entity Gap: Deploy Organization schema with a canonical @id URI, build consistent off-site entity signals (directory listings, press mentions, Wikidata), and align all brand name instances to a single canonical form.
Content Structure Failure: Restructure articles with answer-first opening paragraphs, intent-specific H2 headings phrased as questions or direct statements, and FAQ blocks with standalone answers at the close of each major section.
Schema Absence: Implement Article schema with full author, publisher, datePublished, and dateModified fields. Add FAQPage schema for every Q&A section. Verify with Google’s Rich Results Test and inspect page source for any unpopulated template variables.
Index Lag: Confirm all four preceding failure modes are clear, then continue publishing at regular intervals while the retrieval history builds. Avoid re-engineering content that was correctly structured to begin with — the most common mistake at this stage.
Run the five-question diagnostic above, identify your failure mode, and go to the spoke. The diagnostic process takes about fifteen minutes. The fix depends on which door you walked through.
FAQ
Why isn’t my website showing up in AI search results even though it ranks well on Google?
Google ranking and AI search visibility are different pipelines with different requirements. Google ranks pages based on link authority, relevance signals, and Core Web Vitals. AI systems — ChatGPT, Perplexity, Google AI Overviews — cite content based on crawlability by AI-specific bots, brand entity recognizability, structured data presence, and extraction-ready content formatting. A page can rank on page one of Google and never appear in an AI-generated answer if its AI bot access is blocked, its schema is absent, or its content structure doesn’t match how AI retrieval systems extract passages. The two systems share some infrastructure but have meaningfully different citation requirements.
What causes a website to be invisible to AI search engines?
Five specific failure modes cause AI invisibility: a crawl block that prevents AI bots like OAI-SearchBot or PerplexityBot from reading the site, an entity gap where the brand isn’t recognizable as a named entity to AI systems, content structure failure where articles aren’t formatted for AI extraction, missing or broken schema markup that prevents content classification, and index lag on newly published content. Each failure mode is independent — you can have more than one simultaneously — but crawl block invalidates all downstream signals, so it should always be diagnosed first.
How do AI search engines decide which websites to cite?
AI citation follows a five-stage pipeline: crawl, index, retrieve, extract, cite. At the crawl stage, AI-specific bots need explicit access to the site. At the retrieval stage, entity density, content freshness, and semantic relevance determine whether the page surfaces for a given query. At the extraction stage, the AI system pulls specific passages — favoring answer-first paragraphs, FAQ blocks, and structured definitions. At the citation stage, brand identity must be resolvable through Organization schema and off-site entity signals. Miss any stage and the citation doesn’t happen. Most “AI SEO” advice targets the extraction stage without confirming the preceding stages are functional — which is why it often doesn’t produce results.
Why does my competitor appear in AI answers but I don’t — our content is similar?
Similar content doesn’t mean similar AI visibility. Your competitor’s advantage is almost certainly at the entity or structure layer, not the content quality layer. The most common cause of this gap is that a competitor has deployed Organization schema with a clear @id URI, used consistent canonical brand naming across their site, and has off-site entity signals (directory listings, press mentions, or a Wikidata entry) that allow AI systems to identify them as a named citable source. A second common cause is content structure — their articles lead with direct answers in extraction-ready paragraph format, with FAQ blocks and intent-mapped headings, while comparable content formatted as flowing prose gets passed over during AI extraction even at equal quality.
Why does AI not show my website even after I’ve done SEO optimization?
Standard SEO optimization and AI Citation Engineering address overlapping but distinct problems. SEO optimization — keyword targeting, link building, Core Web Vitals improvements, meta tag optimization — improves Google ranking. AI citation requires different interventions: AI-specific bot access verification, brand entity schema, answer-first content structure, and FAQ markup. It’s common for a well-SEO’d site to have significant AI visibility gaps because the AI-specific requirements were never addressed. The five-question diagnostic in this article identifies which specific requirement is failing.
How long does it take for a new website to appear in AI answers?
AI citation timelines vary by platform and by how many of the five failure modes are resolved. When all failure modes are cleared — crawl access confirmed, brand entity established, content structured for extraction, schema complete — Ideapreneur’s first-party Citation Architecture data shows new content on sites without prior AI citation history typically requires 30–90 days to appear consistently in AI-generated answers. Content on established domains with existing AI citation history tends to surface faster. Perplexity’s real-time RAG pipeline can theoretically surface new content immediately, but citation probability is weighted toward sources with retrieval history. Full timeline analysis covering platform-specific citation windows and first-party data is published in the Citation Architecture spoke series.
Can I have more than one failure mode at the same time?
Yes, and it’s more common than having exactly one. A new brand launching its first content cluster will frequently have an entity gap (no Organization schema, no off-site entity signals), a content structure failure (no FAQ blocks, buried answers), schema absence (no Article or FAQ schema), and index lag simultaneously. The diagnostic sequence in this article is ordered by pipeline stage precisely because earlier failures mask later ones — fixing content structure while a crawl block is active accomplishes nothing. Resolve in order: crawl access first, entity second, structure third, schema fourth.
What is Generative Engine Optimization and how is it different from SEO?
Generative Engine Optimization (GEO) is the practice of optimizing content to be retrieved and cited by AI-powered answer engines — ChatGPT, Perplexity, Google AI Overviews — rather than to rank in traditional search results. Where SEO targets a ranking algorithm, GEO targets an extraction and citation pipeline. The mechanisms overlap — crawlability, content quality, and topical authority matter to both — but GEO adds requirements that SEO doesn’t address: AI-specific bot access, brand entity schema, answer-first content structure, and FAQ markup optimized for extraction. AI Citation Engineering, as developed by Ideapreneur’s Citation Architecture framework, is the systematic implementation of GEO across a content cluster with measurable citation probability targets.
The five failure modes described here — Crawl Block, Entity Gap, Content Structure Failure, Schema Absence, and Index Lag — form the diagnostic backbone of the Citation Architecture framework. Each has a corresponding spoke in this cluster. The pillar identifies. The spokes fix.